微科盟代谢组数据分析结题报告
一 概述
代谢物亦称中间代谢物,是指通过代谢过程产生或消耗的物质,生物大分子不包括在内。代谢组是指生物体内源性代谢物质的动态整体(代谢物的集合)。而传统的代谢概念既包括生物合成,也包括生物分解,因此理论上代谢物应包括核酸、蛋白质、脂类生物大分子以及其他小分子代谢物质。代谢组目前只涉及相对分子质量约小于1000的小分子代谢物质。代谢组学是对某一生物或细胞在一特定生理时期内所有低分子量代谢产物同时进行定性和定量分析的一门新学科。以组群指标分析为基础,以高通量检测和数据处理为手段,以信息建模与系统整合为目标的系统生物学的一个分支。代谢组研究有非靶向和靶向两种,非靶向代谢组学无偏向地检测样本中所有能检测到的代谢物分子,通过生信方法进行差异分析和通路分析,寻找生物标志物。靶向代谢则是针对特定的代谢物进行检测。
对代谢组进行研究,能够考察生物体系在特定时期受到刺激或扰动前后所有小分子代谢物的组成及其含量变化,从而表征生物体系的整体代谢特征。如:糖、有机酸、脂质、维生素、氨基酸、芳香烃等。也可以 研究代谢物表达量的变化,代谢物与生理病理变化的关系,寻找生物标志物,发现代谢途径。
二 项目流程
2.1 实验流程
该实验中我们利用基于气质联用(GC-Q-MS)非靶向的方式研究了样本的代谢组。
- 通过Agilent MSD ChemStation工作站将获得的原始数据转换成netCDF格式(xcms输入文件格式)
- 进行峰识别(peaks identification)、峰过滤(peaks filtration)、峰对齐(peaks alignment)
- 得到包括质核比(mass to charge ratio,m/z)和保留时间(retention time)及峰面积(intensity)等信息的数据矩阵;结合AMDIS程序进行代谢物的注释,注释所用数据库为National Institute of Standards and Technology(NIST)商业数据库和Wiley Registry代谢组数据库,其中代谢物烷烃保留指数根据The Golm Metabolome Database(GMD)(http://gmd.mpimp-golm.mpg.de/)提供的保留指数用于进一步的物质定性,同时大部分物质由标准品进行进一步确认,导出数据至excel(标准品鉴定过的物质为红色字体)进行后续分析。
详细实验步骤参见实验检测报告。
2.2 数据分析流程
本代谢组分析流程基于R语言MetaboAnalystR包[1]。如图2-2,代谢组的数据分析流程如下:
- 样本数据的QC质量控制以及批次校正
- 样本数据的标准化
- 代谢物含量统计(柱形图,热图)
- 无监督的降维分析(PCA)
- 特征代谢物(biomarker)的筛选(PLSDA,OPLSDA,单变量分析,火山图,机器学习)
- 相关分析
- 如果是非靶向代谢组,还可以进行特征代谢物的通路分析(富集分析,拓扑分析,通路图)
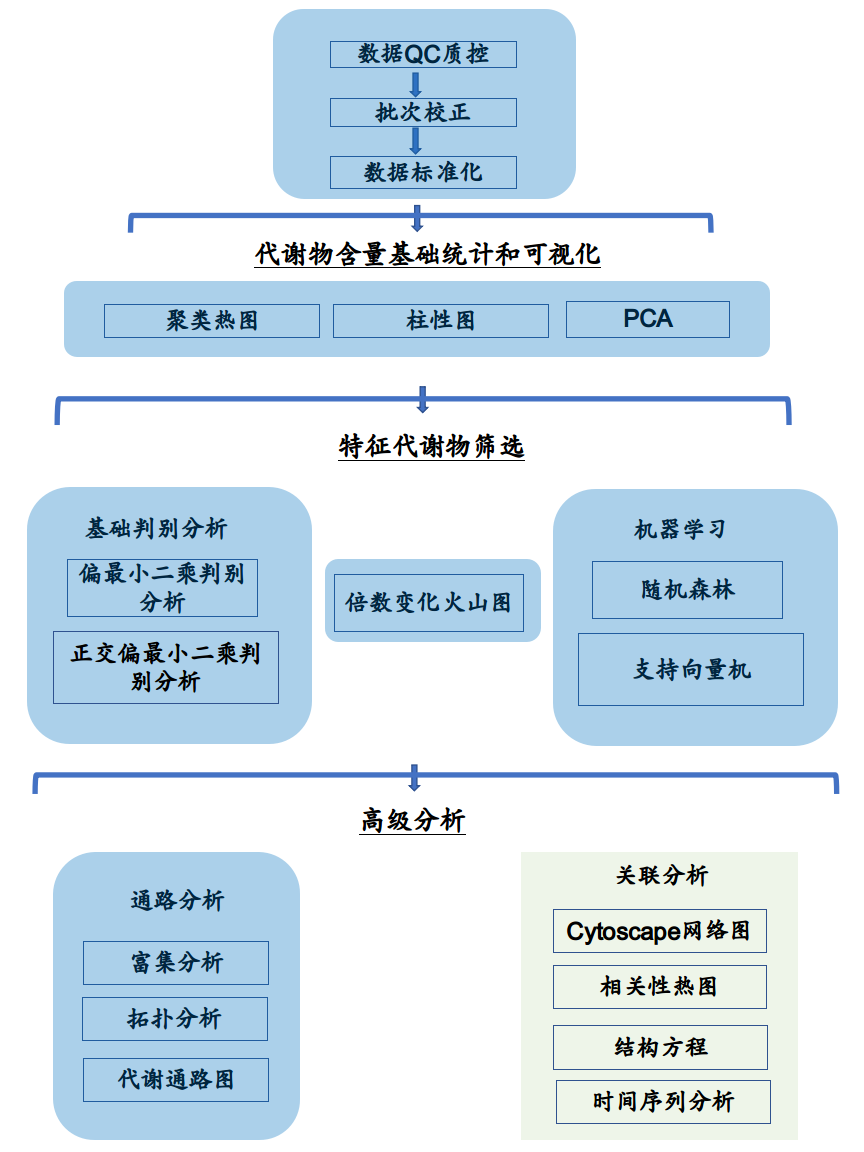
图2-2 代谢组数据分析流程
三 分析结果
除非明确指出,本结题报告的分析内容都使用R语言MetaboAnalystR包 [1]完成
3.1 数据预处理 (00-DataProcess目录)
00-DataProcess/ ├── 01-QA_QC │ ├── AllSample_PC1.svg [第一主成分(PCA)散点图(质量评估图)] │ ├── [分组名]_PCA_QA.svg [对应分组PCA 2D 散点图(质量评估图)] │ ├── [分组名]_PCA_QA_without_ids.svg [对应分组PCA 2D 散点图,同时标注样本名(质量评估图)] │ ├── data_input_after_normalization.tsv [标准化后的代谢物含量表(三步标准化,见后文),即质量评估PCA输入] │ ├── data_input_after_sample_wise_normalization.tsv [经过“样本内校正”后的代谢物含量表] │ ├── data_input.tsv [标准化前的代谢物含量表] │ ├── *_PCA_QC.svg [质量控制效果图(PCA)] │ └── *_PCA_QC_with_ids.svg [质量控制效果图(PCA), 同时标注样本名] ├── 02-Normlization │ ├── compound_wise_normlization.svgdpi300.svg [标准化前后 代谢物在各样本 的含量分布图] │ ├── data_input_after_normalization.tsv [标准化后的代谢物含量表(三步标准化,见后文),对应图中标准化后的含量分布] │ ├── data_input_after_sample_wise_normalization.tsv [经过“样本内校正”后的代谢物含量表] │ ├── data_input.tsv [标准化前的代谢物含量表,对应图中标准化前的含量分布] │ └── sample_wise_normlization.svgdpi300.svg [标准化前后 样本内各代谢物 的含量分布图] └── compound_cross_reference_after_QC.xls
3.1.1 质量评估(QA)和质量控制(QC)(00-DataProcess/01-QA_QC)
利用无监督的主成分分析( Principal Component Analysis , PCA ),我们对每一个组的样品建模,然后展示得分图(score plot, 图3-1-1 )。这种组内的 PCA 分析摒弃了组间的干扰,能让我们更清晰地观察组内的变异并找出可能的离群点( outlier )。图中每个点代表一个样本,而点在图中的位置由该样本中的所有代谢物共同决定。图中的椭圆是基于 Hotelling T2 计算并画出的 95% 置信区间。样本落在椭圆之外暗示该点可能是个离群点。但通常只有在严重离群如将整个模型拉扯得变形时才会考虑删掉该样本。

图3-1-1 各分组PCA得分图
图中每个点代表一个样本,而点在图中的位置由该样本中的所有代谢物共同决定。图中的椭圆是基于 Hotelling T2 计算并画出的 95% 置信区间。样本落在椭圆之外暗示该点可能是个离群点。
也可利用所有样本点PC1值的分布来评估实验室样本制备、样本测量过程是否处于可控的状态。样本点超出控制界限(3 倍标准差)被认为是离群点。如图3-1-2, 通常来说,所有点会在控制界限之内。其中,大部分点会在 2 倍标准差之内围绕 平均值 轴上下波动,少量的点会接近控制界限。在大队列的代谢组学研究中,由于仪器的波动,批次间和日间的变异是很常见的。某一个批次的质控样本和测试样本可能会和其他批次的样本有着明显的偏移。因此,在进行后续的统计分析之前,我们可能需要用指控样本来矫正批次间的变异。但是超出三倍标准差的点通常被认为是离群点。如果是不恰当的样本前处理或是进样引起的,离群点样本需要被重新处理和分析。如若不然,这些样本需要进一步的研究,因为可能是真实的生物学差异引起的这些波动。

图3-1-2 各样本点PC1分布
横坐标为检测样本,纵坐标对应样本在PCA分析中的PC1值。
质量控制是生物分析的基本概念之一,用在保证组学测定的数据的重复性和精确性。由于色谱系统与质谱直接与样品接触, 随着分析样品的增多,色谱柱和质谱会逐步的污染,导致信号的漂移,造成测量的系统误差。通过重复使用同一个质控样本(QC样本)来跟踪整个数据采集过程的行为, 已经被大多数的分析化学领域专家推荐和使用。质控样本被用于评估整个质谱数据在采集过程中的信号漂移, 这些漂移进一步能够被精确的算法所识别,校正,提高数据的质量。本流程采用R语言statTarget包的QC-RFSC算法对各个样本的特征(每个代谢物)信号峰进行校正,并记录了每个代谢物的校正效果。QC样本是所有样本取等量混合后的样本,在信号数据采集过程中,在开头,结尾,以及中间部分位点插入QC样本,记录信号漂移情况。所有QC样本都是一样的,如果没有信号漂移,在数据采集过程中,QC样本的信号强度应该是保持不变的。如图3-1-3所示,校正信号漂移后,如果在PCA图中,QC样本点聚到一起,证明校正效果良好。

图3-1-3 质控样本PCA图
红色点为校正后的质控样本点(QC样本),蓝色点为检测样本。
3.1.2 标准化校正(Normalization)(00-DataProcess/02-Normlization)
在生科云的在线分析中,我们会将是否进行标准化校正的选择权交给用户,然而,我们还是要在这里强调标准化校正的效果和重要性。标准化校正分三步:
- 样本内校正:即样本里所有features的丰度除以该样本的丰度中位数(类似相对丰度计算);这是为了校正library size,在测定过程中,各个样本得到的总代谢物含量差异巨大,而这种差异通常是样本采集和测定过程带来的系统误差,除以中位数,平均值,或者总和,都是校正这种系统误差的常用方式;
- 含量矩阵校正:即对所有含量值进行log转化;T检验以及ANOVA这样的差异比较方法,都要求代谢物含量服从正态分布,因此,我们一般用log转化,使得代谢物含量分布接近正态分布
- feature内校正:即feature对应的所有样本丰度减去该feature丰度均值再除以该feature丰度标准差;feature内校正的目的是使得所有代谢物的均值和标准差(或者说中位数,四分位点,scale)在同一个水平上;PCA,PLSDA,OPLSDA以及机器学习这样的分析,如果不进行代谢物的标准化,那么均值和标准差高的代谢物的重要性将会倾向于高于均值和标准差低的代谢物的重要性,而这样的结果显然不是我们想要的结果,在分组间差异大的才应该是重要性高的。
如图3-1-4所示,在标准化校正前,代谢物含量的中位数和上下四分位点参差不齐,差异较大,但标准化校正后,基本都在同一个水平上了。

图3-1-4 标准化校正前后各个代谢物的含量分布
含量分布用箱线图表示,箱线图从左到右分别对应离群点,最小值,下四分位点,中位数,上四分位点,最大值,离群点。左边图为标准化校正前的分布,右边图为标准化校正后的分布。
3.2 代谢物含量统计(01-ConcentrationSummary目录)
01-ConcentrationSummary
├── 1-Barplot
│ └── [比较组合]
│ ├── barplot.svg [各样本代谢物含量百分比堆积柱形图]
│ ├── Compounds_with_Biological_Roles_barplot.svg [各样本代谢物生物学角色含量百分比堆积柱形图]
│ ├── Compounds_with_Biological_Roles_group_mean_barplot.svg [各分组代谢物生物学角色含量均值百分比堆积柱形图]
│ ├── Compounds_with_Biological_Roles_group_mean_table.txt [各分组代谢物生物学角色含量均值百分比表]
│ ├── Compounds_with_Biological_Roles_table.txt [各样本代谢物生物学角色含量百分比表]
│ ├── group_mean_barplot.svg [各分组代谢物含量均值百分比堆积柱形图]
│ ├── group_mean_table.txt [各分组代谢物含量均值百分比表]
│ └── table.txt [各样本代谢物含量百分比表]
└── 2-Heatmap
└── [比较组合]
├── clustered_heatmap.svg [样本聚类热图]
├── clustered_table.txt [样本聚类热图数据表]
├── group_mean_heatmap.svg [分组均值热图]
├── group_mean_table.txt [分组均值热图数据表]
├── heatmap.svg [样本不聚类热图]
└── table.txt [样本不聚类热图数据表]
3.2.1 百分比含量柱形图(01-ConcentrationSummary/1-Barplot)
计算每个样本内各个代谢物的含量百分比,然后用堆积柱形图可视化,能直观的比较分组之间的代谢物组成结构差异。图3-2-1展示了含量排在前20的代谢物,其余的代谢物被包括进Others中。

图3-2-1 含量前20的代谢物百分比堆积柱形图
横坐标是样品名,根据分组顺序排序,同时用不同颜色标注了不同的分组样本。纵坐标表示各个代谢物的百分比含量,从上而下对应代谢物的柱的顺序与图例一致。
在所有代谢物中,有的代谢物是在生物体内扮演着特定角色的, 比如激素,维生素等。我们将所有代谢物用 KEGG数据库br08001 进行注释,得到代谢物所扮演的生物学角色,然后统计每个生物学角色的百分比含量,绘制百分比含量堆积柱形图,如图3-2-2所示。

图3-2-2 扮演生物学角色的代谢物百分比堆积柱形图
横坐标是样品名,根据分组顺序排序,同时用不同颜色标注了不同的分组样本。纵坐标表示各个生物学角色的百分比含量。
结果文件夹中也提供了分组均值的百分比含量堆积柱形图,请老师自行查看结果文件夹。
3.2.2 热图聚类图(01-ConcentrationSummary/2-Heatmap)
为了研究不同样品间的相似性,还可以通过对样品进行聚类分析从而构建样品的聚类。 选取关注的代谢物(默认选取代谢物含量排名前30),根据样品的代谢物组成,实现样品聚类, 以此考察不同样品或者分组间的相似或差异性;也根据代谢物含量在各样本的分布进行聚类, 寻找代谢物或样本的聚集规律。 如图3-2-3,如果不同分组的样本聚类到不同位置,说明分组间的这30种代谢物组成结构差异较大。

图3-2-3 代谢物热图聚类结果
纵轴为样品名称信息,同时也包括了分组信息。横轴为代谢物。 图中上方的聚类树为代谢物在各样本中分布的相似度聚类,左侧的聚类树为样品聚类树, 中间的热图是代谢物含量热图,颜色与代谢物含量(Z-Score)的关系见图右上方的刻度尺。
结果文件夹中也有不聚类根据样品分组顺序排序的热图,请老师自行查看结果文件夹。
3.3 无监督的PCA分析(02-PCA目录)
02-PCA/
└── [比较组合]
├── data_input_after_normalization.tsv [对应比较组合标准化后的代谢物含量表(三步标准化,见上文),即PCA最终输入]
├── data_input_after_sample_wise_normalization.tsv [对应比较组合经过“样本内校正”后的代谢物含量表]
├── data_input.tsv [对应比较组合标准化前的代谢物含量表]
├── groups_mean.csv [分组均值]
├── pca_loadings.csv [PCA分析各代谢物的载荷(主成分与代谢物的相关性)]
├── pca_score2d_dpi300.svg [PCA 2D 散点图]
├── pca_score2d_with_ids_dpi300.svg [PCA 2D 散点图,同时标注样本名]
├── pca_score3d_dpi300.svg [PCA 3D 散点图]
└── pca_score.csv [PCA散点图中各轴的坐标]
PCA分析是无监督的,也就是说PCA分析并不考虑样品的分组信息。 PCA旨在挑选一些相互独立的能代表所有代谢物的因子(可以理解为所有代谢物的加权和), 这些因子要能最大程度地保留原代谢物的变异信息(方差),挑选保留信息最多的两个因子,画散点图, 能看出各个样本间的代谢物组成结构差异。如图3-3-1,如果图中两个分组的点云(point cloud)明显分布在不同区域,说明两个分组的代谢物组成结构差异较大。

图3-3-1 PCA图
PCA图中,每个点对应一个样本,两个点之间的距离近似与两个样本的代谢物组成结构差异(欧式距离)。不同的分组用不同的颜色标出,椭圆标示的区域是样本点95%置信区域。
3.4 有监督的最小二乘判别分析
3.4.1 偏最小二乘判别分析(03-PLSDA目录)
03-PLSDA/
└── [比较组合]
├── data_input_after_normalization.tsv [对应比较组合标准化后的代谢物含量表(三步标准化,见上文),即PLS-DA最终输入]
├── data_input_after_sample_wise_normalization.tsv [对应比较组合经过“样本内校正”后的代谢物含量表]
├── data_input.tsv [对应比较组合标准化前的代谢物含量表]
├── groups_mean.csv [分组均值]
├── anova_posthoc.csv [多重比较结果,三个以上分组才有,最后一列为差异显著的组合]
├── features_importance.csv [PLS-DA代谢物重要性表]
├── features_importance_fdr_adjusted.svg [PLS-DA代谢物重要性图, 展示FDR校正后的p值]
├── features_importance.svg [PLS-DA代谢物重要性图]
├── model_fitness.csv [PLS-DA模型拟合度参数, R2X, R2Y, Q2等]
├── model_permutation.csv [置换检验结果表]
├── model_permutation.svg [置换检验结果图]
├── score2d_with_ids.svg [2D 散点图, 标注样本名]
├── score2d.svg [2D 散点图]
└── scores.csv [散点图中各个点的坐标]
偏最小二乘判别分析是有监督的,即分析时需要提供分组信息, PLS-DA寻找能够寻找最大程度区分样品分组的因子(因子可以理解为所有代谢物的加权和)。 判别分析将要预测的不连续分类变量编码为一个潜变量,潜变量是连续的, 这样就可以在解释变量和潜变量之间建立回归,用最小二乘回归的理论来求解。 偏最小二乘判别分析是线性判别分析的升级版, 适用于解释变量存在大量共线性问题(共线性会使模型无法求解)的组学数据。 PLS-DA通过投影分别将预测变量和观测变量投影到一个新空间(新空间各个维度间是相互独立,没有共线性问题的), 来寻找一个线性回归模型。
我们采用R语言ropls包[2]进行PLS-DA和OPLS-DA分析。 如图3-4-1,我们用区分效果最好的两个因子来画散点图, 如果不同分组的样本的点云分布在不同区域,说明PLS-DA模型的判别效果较好。

图3-4-1 PLS-DA点云图
图中,每个点对应一个样本,横纵坐标是判别效果最好的两个因子的值。 不同的分组用不同的颜色标出,椭圆标示的区域是样本点95%置信区域。
当样本数远小于代谢物数量时, 只看图3-4-1来判断PLS-DA模型的区分效果(预测能力),不具有说服力, 因为模型很容易过拟合,过拟合即模型在训练样本(训练集,构建PLS-DA模型的样本)中有较好的预测能力, 但对于训练集之外的样本(测试集),预测能力骤减。
参照图3-4-2,评估模型是否可靠有两个方法:
- 通过交叉验证Q2Y(简写为Q2)评估:将数据分为训练集(Training set)、验证集(Validation set) 和测试集(Test set),训练集用于训练模型,验证集优化模型,测试集测试模型的预测能力。 但受限于样本数量,通常采用K折交互验证。我们采用七折交互验证(当样本数小于7时,折数为样本数),即将数据集分为7份, 每次挑选出1份作为验证集,验证模型预测效果,剩余的6份用来训练建模(训练集),整个过程将会被重复直到所有样品都被预测过。 预测的分组标签将会和真实分组标签做对比得到预测残差平方和(Predicted residual sum of squares, PRESS)。 为方便起见,将PRESS转变为Q2(1-PRESS/SS)。图3-4-2中横坐标1对应的纵坐标, 即为最终模型对应的Q2和R2Y, 过拟合的模型通常有较高的R2Y(可理解为模型在训练集中的预测能力), 但Q2不会很高。 对于生物学样本,Q2≥0.4是比较理想的,Q2≥0.2往往也可以接受,只是模型比较弱。 ropls包[2]在自动建模(Autofit)时, 会根据Q2决定模型所用的预测成分个数(OPLS-DA模型则是决定Orthogonal component个数), 逐步增加成分个数,当Q2停止增长,甚至降低时,模型将不再增加成分个数。 当且仅当自动建模得到的预测成分数量大于等于3时,结果文件夹中才会有 score3d.svg 图。
- 通过置换检验评估: 打乱样本的分组标签,构建模型,计算模型的R2Y(简写为R2,可理解为模型在训练集的预测能力) 和Q2Y(简写为Q2,可理解为模型在交叉验证的验证集中的预测能力); 重复多次(默认200次),如果计算得到的R2Y和Q2,大部分都比实际分组标签得到的R2Y和Q2低, 即pR2Y和pQ2小于0.05(p值可以理解为置换得到的R2Y、Q2,大于等于真实分组标签得到的R2Y、Q2的比例), 则可判断模型比较可靠; 也可通过回归分析辅助判断,置换的分组标签越接近真实标签(相似度越高), 得到的R2Y和Q2越高,即回归线斜率为正,截距较小, 则可判断我们真实标签得到的模型不是随机的,是可靠的。

图3-4-2 PLS-DA置换检验分析图
横坐标为置换分组标签与真实分组标签的相似度,即分组标签相同的比例, 纵坐标为每次置换对应的R2Y和Q2, 横坐标1对应的纵坐标,即为最终模型对应的Q2和R2Y。 图中的两条直线分别是R2Y和Q2的回归直线,图例给出了回归方程。
同时也能够寻找在判别分析过程中作用(重要性,VIP, Value Importance in Projection)最大的代谢物,这些代谢物可以作为区分不同分组的biomaker。 一般来说,VIP大于1的代谢物对判别分析的贡献是较大的,这些代谢物在分组间有较大差异。 如图3-4-3,黄色区域中标出代谢物名称的代谢物,是校正后p值小于0.05,VIP大于1的代谢物, 这些代谢物在分组间有显著差异,在PLS-DA中起到重要作用,应该重点关注。

图3-4-3 PLS-DA代谢物重要性图
图中,每个点代表一个代谢物,横坐标是VIP(Value Importance in Projection),纵坐标是FDR校正后的p值(log10转化)。
model_fitness.csv 表格各列解释如下:
- 成分,p开头的是预测成分,o开头的是正交成分,PLS-DA只有预测成分
- "R2X": 各成分对代谢物含量矩阵变异的解释度(方差占比)
- "R2X(cum)": R2X累加,通常最下面那个值作为整个模型最终的R2X
- "R2Y": 各成分对分组变量(响应变量)变异的解释度(方差占比),可理解为模型在训练集的预测能力
- "R2Y(cum)": R2Y累加,通常最下面那个值作为整个模型最终的R2Y
- "Q2": 各成分Q2,可理解为模型在交叉验证的验证集中的预测能力,1-预测残差平方和占比
- "Q2(cum)": Q2累加,通常最下面那个值作为整个模型最终的Q2
model_permutation.csv 表格各列解释如下:
- 置换序号
- "R2X(cum)": 所有成分累加R2X
- "R2Y(cum)": 所有成分累加R2Y
- "Q2(cum)": 所有成分累加Q2
- "RMSEE": 预测的均方根误差
- "pre": 模型预测成分数量
- "ort": 模型正交成分数量,PLS-DA为0
- "sim": 置换的分组标签 与 真实标签的相似度,通常为标签相同的占比(0~1); OPLS-DA应用于三个分组以上时,由于分组需要转换为排序值(即模型变为OPLSR), 相似度为相关系数,即可能为负(-1~1)
features_importance.csv 表格各列解释如下:
- 代谢物名称
- "VIP": 代谢物在模型中的重要性
- "t.stat": T检验统计量, 两个分组才有
- "f.stat": ANOVA统计量, 三个以上分组才有
- "p.value": T检验(三个以上分组为ANOVA)p值
- "-log10(p)": -log10(p值)
- "FDR": FDR校正后的p值
- "-log10(FDR adjusted p)":-log10(FDR校正后的p值)
anova_posthoc.csv 表格各列解释如下:
- 代谢物名称
- "f.value": ANOVA统计量
- "p.value": ANOVA检验p值
- "-log10(p)": -log10(p值)
- "FDR": FDR校正后的p值
- "Fisher's LSD": Fisher's LSD多重比较显著(p<0.05)的组合
3.4.2 正交偏最小二乘判别分析(04-OPLSDA目录)
04-OPLSDA/
└── [比较组合]
├── data_input_after_normalization.tsv [对应比较组合标准化后的代谢物含量表(三步标准化,见上文),即OPLS-DA最终输入]
├── data_input_after_sample_wise_normalization.tsv [对应比较组合经过“样本内校正”后的代谢物含量表]
├── data_input.tsv [对应比较组合标准化前的代谢物含量表]
├── groups_mean.csv [分组均值]
├── anova_posthoc.csv [多重比较结果,三个以上分组才有,最后一列为差异显著的组合]
├── features_importance.csv [OPLS-DA代谢物重要性表]
├── features_importance_fdr_adjusted.svg [OPLS-DA代谢物重要性图, 展示FDR校正后的p值]
├── features_importance.svg [OPLS-DA代谢物重要性图]
├── model_fitness.csv [OPLS-DA模型拟合度参数, R2X, R2Y, Q2等]
├── model_permutation.csv [置换检验结果表]
├── model_permutation.svg [置换检验结果图]
├── score2d_with_ids.svg [2D 散点图, 标注样本名]
├── score2d.svg [2D 散点图]
└── scores.csv [散点图中各个点的坐标]
OPLS-DA与PLS-DA类似,与PLS-DA相比, OPLS-DA的不同之处在于只利用代谢组数据的一个成分(因子,componet)去预测分组(响应变量), 而其他成分都用来描述与分组(响应变量)正交的(无关的)变异[3], 增加了各个成分的可解释性。
OPLS-DA结果图和表和PLS-DA相似,请参照PLS-DA部分进行解读

图3-4-4 OPLS-DA置换检验分析图
横坐标为置换分组标签与真实分组标签的相似度, 通常为标签相同的占比(0~1); OPLS-DA应用于三个分组以上时,由于分组需要转换为排序值(即模型变为OPLSR), 相似度为相关系数,可能为负(-1~1)。 纵坐标为每次置换对应的R2Y和Q2, 横坐标1对应的纵坐标,即为最终模型对应的Q2和R2Y。 图中的两条直线分别是R2Y和Q2的回归直线,图例给出了回归方程。
需要注意的是,OPLS-DA不能用于三个以上分组, 但对于三个以上分组,我们将分组变量转换为 排序值,使用OPLSR进行分析,得到类似的分析结果, 但由于排序和分组名称有关,使得分组名会影响分析结果。
3.5 单变量分析(05-UnivariateAnalysis目录)
05-UnivariateAnalysis/
└── [比较组合]
├── data_input_after_normalization.tsv [对应比较组合标准化后的代谢物含量表(三步标准化,见上文),即计算T/ANOVA p值的数据]
├── data_input_after_sample_wise_normalization.tsv [对应比较组合经过“样本内校正”后的代谢物含量表,即计算FC的数据(FC计算不能使用负数)]
├── data_input.tsv [对应比较组合标准化前的代谢物含量表]
├── groups_mean.csv [分组均值]
├── Significant_features_boxplot.svg [显著差异代谢物箱线图,最多展示前25个]
├── t_test.csv [T 检验结果表]
├── Volcano_features_importance.svg [火山图]
├── Volcano_features_significance.csv [火山图对应表格]
└── Volcano_features_significance_dpi300.svg [火山图简略版,不带背景颜色,只标注最显著前10代谢物名]
某些情况下,我们不仅想知道代谢物在分组间是否发生了变化(差异是否显著),同时也想知道这个变化有多大, 以此来评估代谢物变化会给生物体造成多大的影响。我们可以通过计算代谢物变化的倍数(Fold Change, FC)来衡量这个变化的大小,结合p值,来筛选一些重点关注的代谢物。 默认情况下,我们会将分组信息表中, 写在前面(上方)的分组作为参照, 计算另一个分组的均值和参照组的均值的变化倍数,上调变化倍数为正,下调倍数为负。如图3-5-1, 黄色区域的代谢物是p值(未校正)小于0.05,log2(FC)绝对值大于1的代谢物, 这些代谢物在分组间差异显著,且变化较大,应该重点关注。

图3-5-1 倍数变化火山图
每个点代表一个代谢物,横坐标为变化倍数,纵坐标为T检验p值,变化倍数越大,p值越小(log10(p)越高),点越大。
为了直观地展示代谢物在组之间的差异,我们对单维统计分析获得的排名靠前(P值较小的前25)的代表性的差异代谢物的作箱式图,如下图3-5-2所示。

图3-5-2 代谢物差异箱式图
*,**,***分别对应p<0.05, p<0.01, p<0.001
3.6 机器学习
机器学习也属于判别分析,它是判别分析的延伸, 与PLS-DA, OPLS-DA相比, 机器学习是相对较大的模型,能够更好拟合更复杂的数据关系,但对于简单的数据(如样本量少,代谢物数量少), 也更容易过拟合,如果生物学重复较少,建议不参考本部分结果。 常见的机器学习方法有支持向量机,随机森林,神经网络等。
3.6.1 随机森林(06-RandomForest目录)
06-RandomForest/
└── [比较组合]
├── data_input_after_normalization.tsv [对应比较组合标准化后的代谢物含量表(三步标准化,见上文),即随机森林最终输入]
├── data_input_after_sample_wise_normalization.tsv [对应比较组合经过“样本内校正”后的代谢物含量表]
├── data_input.tsv [对应比较组合标准化前的代谢物含量表]
├── RF_features_importance.csv [随机森林模型中,代谢物重要性表]
└── RF_features_importancedpi300.svg [随机森林模型中,代谢物重要性图]
随机森林算法是套袋法(bagging)和决策树的结合,大致过程如下:
- 从原始样本集中使用Bootstraping方法随机抽取n个训练样本,共进行k轮抽取,得到k个训练集(k个训练集之间相互独立,元素可以有重复);
- 对于k个训练集,我们训练k个决策树;
- 在验证集中,每个样本的分类由k个决策树投票决定(每个决策树的权重一样)。
结果文件夹中,图“RF_outliersdpi300.pdf”中标出了在随机森林分析中,容易判别出错的样本名称,这些样本和组内其他样本差异较大。
在随机森林分析中,我们用“Mean Decrease Accuracy”和“Mean Decrease Gini”来衡量一个代谢物在随机森林中判别分组的重要性。把一个代谢物的取值变为随机数,随机森林预测准确性的降低程度就是“Mean Decrease Accuracy”;“Mean Decrease Gini”则是一个代谢物对分类树所有节点上观测值的异质性的影响。两个值越大,代谢物在随机森林中的重要性越大。图3-6-1显示了在随机森林中最重要的15种代谢物,这些代谢物应该在分组之间有较大的差异。

图3-6-1 随机森林中最重要的15种代谢物
左边图的横坐标是“Mean Decrease Accuracy”,它衡量了一个代谢物在随机森林中的重要性;右边图是15中代谢物在两个分组里的含量的热图。
3.6.2 支持向量机(07-SupportVectorMachine目录)
07-SupportVectorMachine
└── [比较组合]
├── data_input_after_normalization.tsv [对应比较组合标准化后的代谢物含量表(三步标准化,见上文),即支持向量机最终输入]
├── data_input_after_sample_wise_normalization.tsv [对应比较组合经过“样本内校正”后的代谢物含量表]
├── data_input.tsv [对应比较组合标准化前的代谢物含量表]
├── SVM_features_importance.csv [SVM 代谢物重要性表]
├── svm_features_importance_dpi300.svg [SVM中最重要的15种代谢物图]
└── svm_roc_all_models_dpi300.svg [SVM ROC 曲线]
支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器, 间隔最大使它有别于感知机;SVM还包括核技巧,这使它成为实质上的非线性分类器。 SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题, 也等价于正则化的合页损失函数的最小化问题。SVM的的学习算法就是求解凸二次规划的最优化算法。
SVM模型的最终预测效果可以用ROC曲线来表示,如图3-6-2。AUC曲线下面积越接近1, 说明模型预测效果越好,也说明分组间代谢物的差异越大。

图3-6-2 SVM ROC 曲线
横坐标为准确度,纵坐标为敏感度,准确度和敏感度越高,模型在训练集的预测效果越好。 AUC为曲线下面积,曲线下面积越接近1,模型在训练集的预测效果越好。 如果样本数较少,模型容易过拟合,AUC都等于1,但不意味着模型在新的测试样本中有 好的表现,请谨慎解读
同时,我们用套袋法和SVM结合,即用Bootstraping的到k个训练集, 在每个训练集里独立挑选最重要的代谢物训练SVM。 计算每个代谢物在k个训练集中被选中的频率,这个频率可以用来衡量代谢物在SVM分析中的重要性, 同时也可以计算代谢物在所有训练集中的平均重要性。图3-6-3展示了在SVM分析中最重要的15个代谢物, 这些代谢物在分组间应该有较大差异。

图3-6-3 SVM中最重要的15种代谢物
左边图的横坐标是SVM平均重要性,右边图是15中代谢物在两个分组里的含量的热图。
3.7 相关分析(08-CorrelationAnalysis目录)
08-CorrelationAnalysis
├── all_group_clustered_pearson_cor_heatmap.svg [所有分组代谢物相关性热图, 根据相关系数聚类]
├── all_group_pearson_cor_heatmap.svg [所有分组代谢物相关性热图]
├── data_input_after_normalization.tsv [所有分组标准化后的代谢物含量表(三步标准化,见上文),即相关分析最终输入]
├── data_input_after_sample_wise_normalization.tsv [所有分组经过“样本内校正”后的代谢物含量表]
├── data_input.tsv [所有分组标准化前的代谢物含量表]
├── fdr_adjusted_p_value_matrix.txt [所有分组, FDR校正后的相关系数p值]
├── pearson_cor_matrix.txt [所有分组代谢物pearson相关系数矩阵]
└── [分组名]
├── clustered_pearson_cor_heatmap.svg [对应分组代谢物相关性热图, 根据相关系数聚类]
├── data_input_after_normalization.tsv [对应分组标准化后的代谢物含量表(三步标准化,见上文),即相关分析最终输入]
├── data_input_after_sample_wise_normalization.tsv [对应分组经过“样本内校正”后的代谢物含量表]
├── data_input.tsv [对应分组标准化前的代谢物含量表]
├── fdr_adjusted_p_value_matrix.txt [对应分组, FDR校正后的相关系数p值]
├── pearson_cor_heatmap.svg [对应分组代谢物相关性热图]
└── pearson_cor_matrix.txt [对应分组代谢物pearson相关系数矩阵]
通过对比每一个组的代谢物相关性分析谱图, 我们可以观察代谢物的相关性在不同组间是否有变化。 因为在病理条件下,某些代谢物之间的相关性可能会改变, 如从正相关变为不相关或负相关。这将会提示我们关注在这些代谢物所在的通路。 我们提供了单个分组以及所有分组一起的pearson相关分析结果的表格, 聚类和不聚类的热图,如图3-7-1是所有分组一起的聚类的相关性热图。

图3-7-1 Pearson相关性热图
总含量前100的代谢物的相关系数矩阵,相关系数由颜色表示,红色正相关,绿色负相关。
3.8 代谢通路分析(09-PathwayTopoEnrichment目录)
09-PathwayTopoEnrichment/
└── [比较组合]
├── data_input_after_normalization.tsv [对应比较组合标准化后的代谢物含量表(三步标准化,见上文),即T检验输入表]
├── data_input_after_sample_wise_normalization.tsv [对应比较组合经过“样本内校正”后的代谢物含量表]
├── data_input.tsv [对应比较组合标准化前的代谢物含量表]
├── groups_mean.csv [分组均值]
├── ora_hyper_score_dpi300.svg [富集分析p值条形图]
├── pathway_enrichment_and_topo_impact.svg [ORA富集分析和拓扑分析气泡图,同时展示p值和impact]
├── pathway_enrichment_and_topo_results.csv [对应富集分析气泡图的数据表]
├── selected_compounds.csv [T检验挑选的,差异显著(p<0.05)的代谢物,即富集分析输入代谢物集合]
├── [代谢通路名称]_dpi301.svg [显著富集通路的代谢物反应网络]
├── [代谢通路名称]hsa00290.html [显著富集通路的代谢通路网页,鼠标悬浮显示代谢物ID]
└── [代谢通路名称]hsa00290.png [显著富集通路的代谢通路图]
3.8.1 富集分析
富集分析的目的寻找在某个生物学过程中起关键作用的生物通路, 从而揭示和理解生物学过程的基本分子机制。对于代谢组数据, 在富集分析之前,我们需要挑选一些重点关注的代谢物, 这些代谢物通常需要满足两个条件:
- 是那些在分组间有显著差异(T检验,p<0.05)的代谢物;
- 代谢物需要物参与图3-8-3中的化合物反应网络 (KEGG Compound Reaction Network,它内嵌于KEGG Pathway(图3-8-4)中)。 挑好关注的代谢物集合后,再看这些代谢物都在哪些代谢通路(KEGG物种特异性代谢通路, 不同物种的代谢通路略有区别)中出现,通过计算这些代谢通路的ORA (Over-Representation Analysis,过表达分析)p值,判断关注的代谢物是否在这些代谢通路中显著富集。 图3-8-1中显示了差异代谢物显著富集的代谢通路。这些代谢通路可能在所研究的生物学过程中有重要意义。

图3-8-1 ORA富集分析
横坐标为富集倍数,它是代谢通路中, 观测代谢物数/理论代谢物数。 p值的大小用颜色表示,颜色越深,p值越小。
3.8.2 拓扑分析
即便关注的代谢物在某个通路中显著富集, 我们仍然不知道这些代谢物在这个代谢通路中是否起到关键作用, 代谢物对代谢通路究竟有多大影响(Impact)。 拓扑分析能够计算关注的代谢物在代谢通路中的作用大小(用Impact衡量)。 例如,如果代谢通路中,一个代谢物下游没有其他任何代谢物或基因, 那么我们可以判断这个代谢物对代谢通路的影响基本为零。相反, 如果一个代谢物非常靠近上游,且下游有很多其他代谢物和基因,那么这个代谢物对代谢通路的影响一定很大。 Impact本质是化合物反应通路中(图3-8-3)所有显著差异代谢物相对出度(relative out degree, 即先算每个代谢物的out degree(直接相连的下游代谢物的数目), 再除以通路中所有代谢物的out degree总和)的总和。我们通常将拓扑分析和富集分析结合起来, 从而判断一个代谢通路是否在所研究的生物学过程中起到关键作用。 图3-8-2中蓝色区域的代谢通路是ORA富集分析中显著的代谢通路,纵坐标展示了这些代谢通路在拓扑分析中的Impact。

图3-8-2 ORA富集分析和拓扑分析
横坐标为ORA分析p值,蓝色区域是显著的(p<0.05);纵坐标为拓扑分析Impact。
3.8.3 代谢通路图
代谢通路图能够比较直观的反映代谢物的上下游关系,作用模式, 以及代谢通路的拓扑结构,同时能找到与代谢物关联的基因。图3-8-3是化合物反应网络(物种特异), 红色代谢物是关注的代谢物,即在分组间有显著差异的代谢物,每个箭头都由底物指向产物, 双向箭头代表该反应可逆,这个网络是代谢组学研究里关注的主要网络, 也是富集分析里富集的主要对象。图3-8-4是同时包含代谢物和基因的代谢通路(KEGG完整的代谢通路,不区分物种), 基因表达翻译的蛋白通常在化合物反应中扮演酶的角色,有颜色的代谢物是在分组间有显著差异的代谢物, 颜色对应分组,表示在对应分组中代谢物含量较高(相对其它分组)。对于同一个KEGG Pathway, 图3-8-4包含的代谢物通常比图3-8-3多,一方面因为图3-8-4不区分物种,相当于所有物种的并集,另一方面, 图3-8-4中的某些代谢物(化合物)是不参与图3-8-3中的化合物反应的。

图3-8-3 化合物反应网络
每个箭头都由底物指向产物,双向箭头代表该反应可逆。红色代谢物是在分组间有显著差异的代谢物。
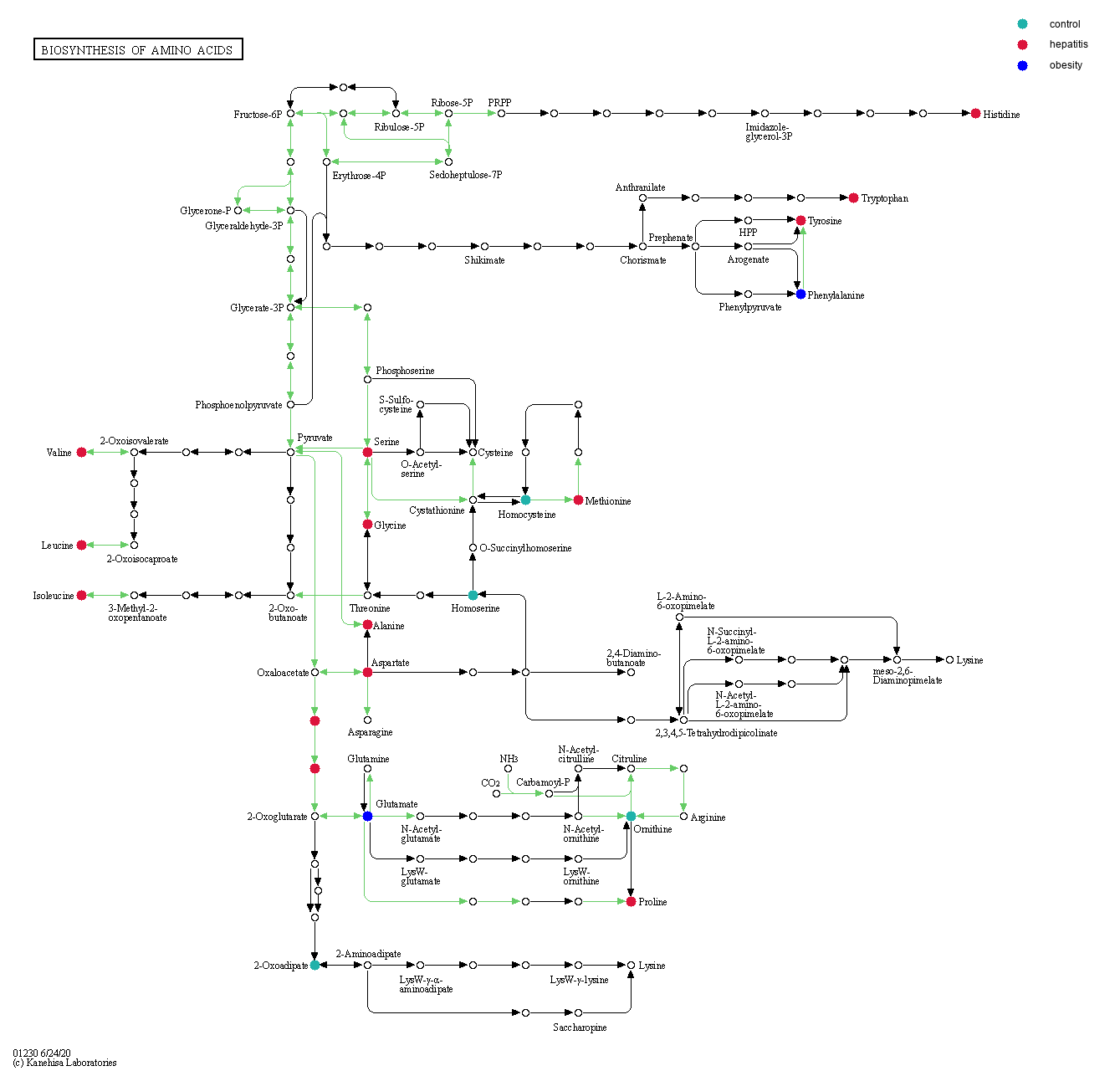
图3-8-4 代谢物和基因的代谢通路
有颜色的代谢物是在分组间有显著差异的代谢物,颜色对应分组, 表示在对应分组中代谢物含量较高(相对其它分组)。
四 分析所用软件的版本
| 软件 | 版本 |
|---|---|
| MetaboAnalystR | 2.0.1 |
| ropls | 1.18.8 |