微科盟原核有参转录组数据分析结题报告
一 概述
转录组是指特定组织或细胞在某个时间或某个状态下转录出来的所有RNA的总和,主要包括mRNA和非编码RNA。原核转录组学是在RNA水平上的表达情况,研究生物在不同环境、宿主等情况下的基因表达变化,从而阐述宿主和环境对生物的影响。随着基因测序技术的发展与测序成本的降低,RNA-Seq凭借高通量、高灵敏度、应用范围广等优势,已经成为转录组研究的主要方法。
原核有参转录组测序采用Illumina测序平台,对原核生物的所有RNA进行测序,将高质量数据与参考基因组进行比对,进一步进行表达定量、功能注释、变异分析等分析。转录组研究是基因功能及结构研究的基础和出发点,原核有参转录组物种的转录水平变化、分子机制及调控网络研究提供了有力的技术手段,目前已广泛应用于基础研究、临床诊断、药物研发等领域。
二 项目流程
2.1 测序实验流程
从RNA样品提取到最终数据获得,样品检测、建库、测序等每一环节都会直接影响数据的数量和质量,从而影响后续信息分析的结果。为从源头保证测序数据准确可靠,我们承诺在数据的所有生产环节都严格把关,从根源上确保高质量数据的产出。建库测序的流程图如下(图2.1):
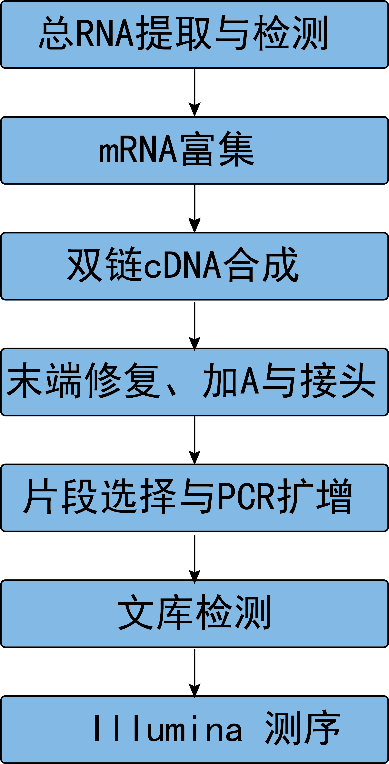
图2.1 RNA-Seq建库测序流程
2.1.1 RNA提取与检测
采用标准提取方法从组织或细胞中提取RNA,随后对RNA样品进行严格质控。质控使用Agilent 5400 bioanalyzer,精确检测RNA完整性。
2.1.2 文库构建与质检
文库构建
利用原核生物大部分mRNA都带有多聚腺苷酸尾的结构特征,通过连接有寡聚胸腺嘧啶磁珠富集带有多聚腺苷酸尾的mRNA,进行链特异性建库(图2.2)。
- 链特异性建库:以片段化的mRNA为模版,随机寡核苷酸为引物,在M-MuLV逆转录酶体系中合成cDNA第一条链,在合成第二条链时,dNTPs中的dTTP由dUTP取代,之后同样进行cDNA末端修复、加A尾、连接测序接头和长度筛选,然后先使用USER酶降解含U的cDNA第二链再进行PCR扩增并获得文库。链特异性文库具有诸多优势,如相同数据量下可获取更多有效信息;能获得更精准的基因定量、定位与注释信息;能提供反义转录本及每一isoform中单一exon的表达水平。建库原理如下面右图所示:
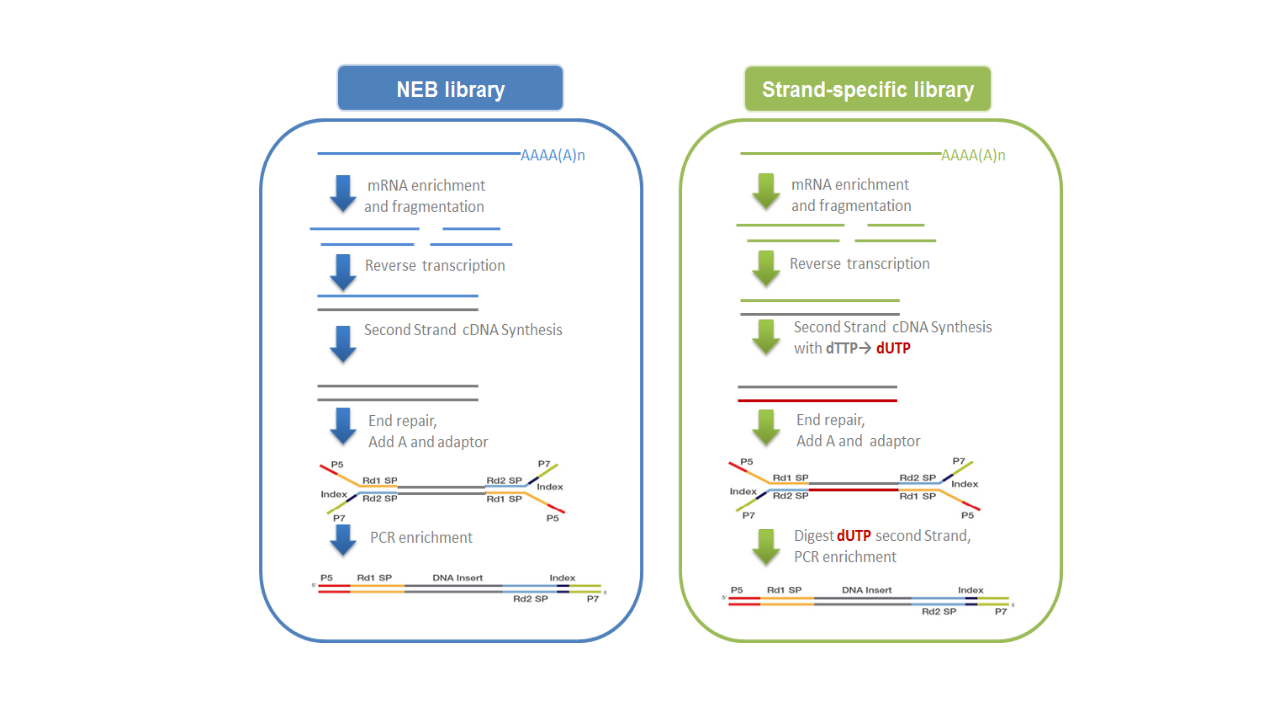
图2.2 文库构建原理示意图
测序接头:包括P5/P7,index和Rd1/Rd2 SP三个部分(如上图所示)。其中P5/P7是PCR扩增引物及flow cell上引物结合的部分,index提供区分不同文库的信息,Rd1/Rd2 SP即read1/read2 sequence primer,是测序引物结合区域,测序过程理论上由Rd1/Rd2 SP向后开始进行。
文库质检
文库构建完成后,先使用Qubit2.0 Fluorometer进行初步定量,稀释文库至1.5ng/ul,随后使用Agilent 5400 bioanalyzer对文库的insert size进行检测,insert size符合预期后,qRT-PCR对文库有效浓度进行准确定量(文库有效浓度高于2nM),以保证文库质量。
2.1.3 上机测序
库检合格后,把不同文库按照有效浓度及目标下机数据量的需求pooling后进行Illumina测序。测序的基本原理是边合成边测序(Sequencing by Synthesis)。在测序的flow cell中加入四种荧光标记的dNTP、DNA聚合酶以及接头引物进行扩增,在每一个测序簇延伸互补链时,每加入一个被荧光标记的dNTP就能释放出相对应的荧光,测序仪通过捕获荧光信号,并通过计算机软件将光信号转化为测序峰,从而获得待测片段的序列信息。测序过程如下图所示(图2.3):
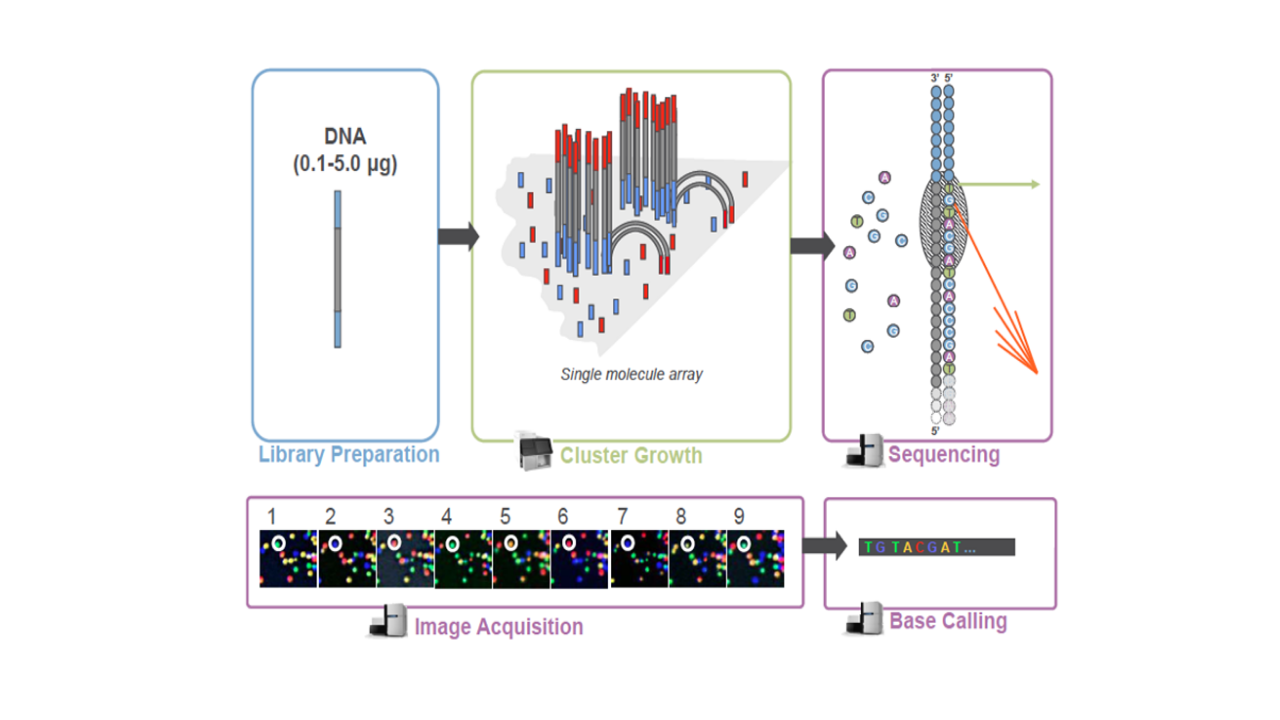
图2.3 Illumina测序原理示意图
2.2 生信分析流程
RNA-seq的核心是基因表达差异的显著性分析,使用统计学方法,比较两个条件或多个条件下的基因表达差异,从中找出与条件相关的特异性基因,然后进一步分析这些特异性基因的生物学意义,分析过程包括质量控制、序列比对、表达水平定量、差异分析、功能富集等环节。另外变异位点也是RNA-seq的重要分析内容。同时,根据不同的研究需求,推出转录组个性化分析内容,如基因共表达网络构建(WGCNA)、基因集富集分析(GSEA)、ipath 代谢途径可视化分析等。信息分析流程如下图所示:
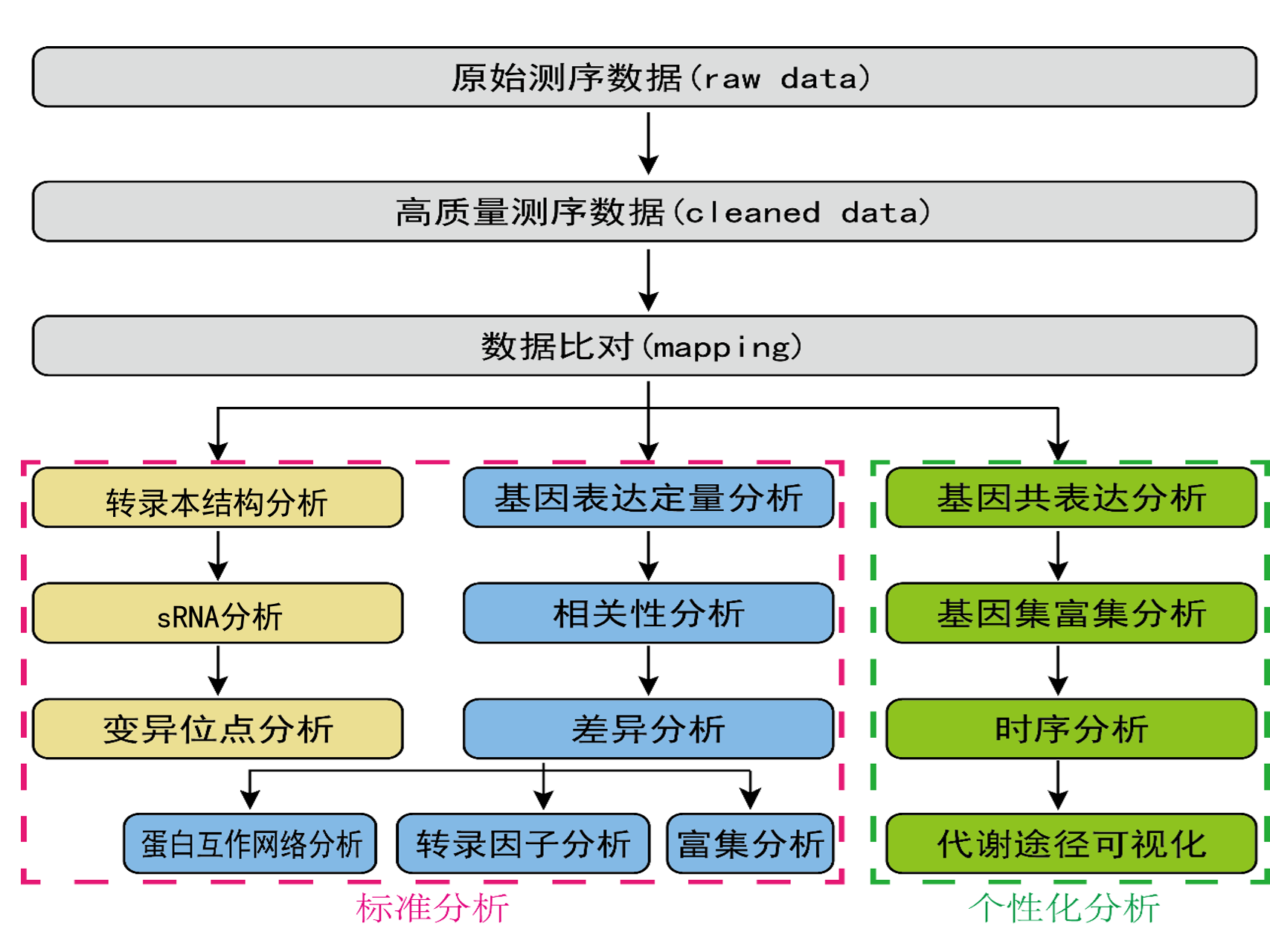
图2.4 RNA-Seq信息分析技术流程
三 结果文件夹解读
3.1 数据质量控制
01.QC/ ├── summary_before_filtering.xls [各样本质控前质量情况汇总] ├── summary_after_filtering.xls [各样本质控后质量情况汇总]
质控
用fastp软件[1]对每一个样本的测序数据raw data做质控处理(参数: --overrepresentation_analysis --trim_front1 2 --trim_front2 2 --cut_front --cut_tail --cut_window_size 3 --cut_mean_quality 30),得到clean data用于下游分析,质控规则如下:
- 对整条read做保留或弃去处理
- 根据碱基质量值弃去低质量的整条read
- 当一条read中N碱基的个数达到一定的数量(默认为5个)时,弃去整一条read;
- 当一条read中低质量碱基(默认质量值低于15的碱基为低质量碱基)达到一定的比例(默认这个比例值为40%)时,弃去整一条read。
- 根据read长度弃去低质量的整条read
- 当一条read的碱基个数少于一定的数量(默认为15个碱基)时,弃去整一条read。
- 对read做局部裁剪
- 强制性删除头部和尾部各2个碱基
- 因为测序反应一般起始和结束阶段的碱基质量是最差的,所以我们统一裁剪掉read1和read2它们各自的5'端的2个碱基、3'端的2个碱基。
- 根据碱基质量值删除滑动窗口内的碱基
- 一般来说,测出来的read,开头的碱基质量差,然后随着测序反应的稳定,碱基质量会逐步上升,后面随着反应时间的延长、化学产物的积累、酶受到的环境不利影响的积累,到后面碱基质量会下降,所以需要对read的开头和结尾的低质量碱基区做裁剪。
- 我们以3个碱基的长度为一个窗口的大小,从read的头部向尾部滑动,计算窗口内的3个碱基的平均质量值,如果平均质量值小于阈值30,那么表明当前窗口的碱基质量差,就删除这个窗口内的所有的3个碱基,然后滑动到下一组的3个碱基,计算平均质量值,做类似的删除处理;如果当前的窗口的平均质量值大于或等于30,那么表明当前窗口的碱基质量足够好了,于是停止滑动窗口,保留这个窗口以及后面的所有碱基。同理,从read的尾部向头部,也做类似的滑动窗口删除碱基的处理。
- adapter序列裁剪
- 默认情况下,对pair-end 的read1和read2做两序列比对,查看比对结果中,read1的右端是否会超出read2的右端,read2的左端是否会超出read1的左端,如果超出的话,表明是测到了adapter序列,则会把超出的部分给剪掉。
将所有样本的质控信息做提取整合,生成总体的样本测序数据质控信息统计表。
表3-1-1 各样本质控前质量情况汇总(summary_before_filtering.xls)
| sample id | total reads | total bases | total giga bases | q20 bases | q30 bases | q20 rate | q30 rate | read1 mean length | read2 mean length | gc content |
|---|---|---|---|---|---|---|---|---|---|---|
| DRS_0_da_1 | 25751794 | 1303048248 | 1.3G | 1283490787 | 1251986583 | 0.984991 | 0.960814 | 50 | 50 | 0.360190 |
| DRS_0_da_2 | 26731024 | 1352683874 | 1.35G | 1331789711 | 1298607041 | 0.984554 | 0.960023 | 50 | 50 | 0.370348 |
| DRS_0_da_3 | 28253694 | 1429254188 | 1.43G | 1407906653 | 1373847119 | 0.985064 | 0.961234 | 50 | 50 | 0.388609 |
| DRS_4_da_1 | 25619018 | 1296039418 | 1.3G | 1275659591 | 1243367702 | 0.984275 | 0.959359 | 50 | 50 | 0.380782 |
| DRS_4_da_2 | 25025372 | 1266046323 | 1.27G | 1246577399 | 1215592959 | 0.984622 | 0.960149 | 50 | 50 | 0.391112 |
| DRS_4_da_3 | 27888534 | 1410744700 | 1.41G | 1389114778 | 1354916345 | 0.984668 | 0.960426 | 50 | 50 | 0.391868 |
| WT_0_da_1 | 24232724 | 1226412657 | 1.23G | 1207142159 | 1176483449 | 0.984287 | 0.959288 | 50 | 50 | 0.358271 |
| WT_0_da_2 | 26531992 | 1342950289 | 1.34G | 1322681786 | 1290191639 | 0.984907 | 0.960714 | 50 | 50 | 0.359222 |
| WT_0_da_3 | 24170358 | 1223131056 | 1.22G | 1203581328 | 1173030665 | 0.984017 | 0.959039 | 50 | 50 | 0.366770 |
| WT_4_da_1 | 24967092 | 1263160891 | 1.26G | 1244625632 | 1214755865 | 0.985326 | 0.961679 | 50 | 50 | 0.373600 |
| WT_4_da_2 | 27277596 | 1379556371 | 1.38G | 1357047812 | 1322142606 | 0.983684 | 0.958382 | 50 | 50 | 0.407188 |
| WT_4_da_3 | 30295560 | 1531940349 | 1.53G | 1508269774 | 1471137674 | 0.984549 | 0.960310 | 50 | 50 | 0.402051 |
- sample id: 样本ID
- total reads: 样本序列总数
- total bases: 样本碱基总数
- total giga bases: 样本碱基总数(G为单位)
- q20 bases: 质量分高于20(错误率0.01)的碱基总数
- q30 bases: 质量分高于30(错误率0.001)的碱基总数
- q20 rate: 质量分高于20(错误率0.01)的碱基占比(Q20)
- q30 rate: 质量分高于30(错误率0.001)的碱基占比(Q30)
- read1 mean length: read1平均长度
- read2 mean length: read2平均长度
- gc content: GC含量
表3-1-2 各样本质控后质量情况汇总(summary_after_filtering.xls)
| sample id | total reads | total bases | total giga bases | q20 bases | q30 bases | q20 rate | q30 rate | read1 mean length | read2 mean length | gc content |
|---|---|---|---|---|---|---|---|---|---|---|
| DRS_0_da_1 | 25705328 | 1188285883 | 1.19G | 1174168065 | 1146224383 | 0.988119 | 0.964603 | 46 | 46 | 0.350138 |
| DRS_0_da_2 | 26679734 | 1233084014 | 1.23G | 1218057769 | 1188715567 | 0.987814 | 0.964018 | 46 | 46 | 0.360784 |
| DRS_0_da_3 | 28199738 | 1303281535 | 1.3G | 1287900016 | 1257730577 | 0.988198 | 0.965049 | 46 | 46 | 0.379127 |
| DRS_4_da_1 | 25567596 | 1181230235 | 1.18G | 1166549959 | 1137966639 | 0.987572 | 0.963374 | 46 | 46 | 0.370754 |
| DRS_4_da_2 | 24975612 | 1154102418 | 1.15G | 1140101215 | 1112666880 | 0.987868 | 0.964097 | 46 | 46 | 0.381219 |
| DRS_4_da_3 | 27834176 | 1286024776 | 1.29G | 1270519921 | 1240316809 | 0.987944 | 0.964458 | 46 | 46 | 0.382822 |
| WT_0_da_1 | 24182292 | 1117695475 | 1.12G | 1103865136 | 1076750755 | 0.987626 | 0.963367 | 46 | 46 | 0.349186 |
| WT_0_da_2 | 26483202 | 1224527773 | 1.22G | 1209911293 | 1181145766 | 0.988064 | 0.964572 | 46 | 46 | 0.350488 |
| WT_0_da_3 | 24118702 | 1114462446 | 1.11G | 1100459090 | 1073500719 | 0.987435 | 0.963245 | 46 | 46 | 0.357771 |
| WT_4_da_1 | 24923920 | 1152234050 | 1.15G | 1138819061 | 1112306028 | 0.988357 | 0.965347 | 46 | 46 | 0.363124 |
| WT_4_da_2 | 27215978 | 1256547388 | 1.26G | 1240505578 | 1209774072 | 0.987233 | 0.962776 | 46 | 46 | 0.396764 |
| WT_4_da_3 | 30233108 | 1396334730 | 1.4G | 1379367500 | 1346555483 | 0.987849 | 0.964350 | 46 | 46 | 0.391862 |
- sample id: 样本ID
- total reads: 样本序列总数
- total bases: 样本碱基总数
- total giga bases: 样本碱基总数(G为单位)
- q20 bases: 质量分高于20(错误率0.01)的碱基总数
- q30 bases: 质量分高于30(错误率0.001)的碱基总数
- q20 rate: 质量分高于20(错误率0.01)的碱基占比(Q20)
- q30 rate: 质量分高于30(错误率0.001)的碱基占比(Q30)
- read1 mean length: read1平均长度
- read2 mean length: read2平均长度
- gc content: GC含量
3.2 比对参考基因组
02.Mapping/ ├── ref_alignment_stat.tsv [各样本序列比对情况汇总] ├── rRNA_stat.tsv [各样本核糖体污染评估] ├── geneBody_coverage.geneBodyCoverage.curves.png [基因覆盖度分析结果图] └── geneBody_coverage.geneBodyCoverage.heatMap.png [基因覆盖度分析结果热图]
3.2.1 核糖体污染评估
使用bowtie2软件[3] 将质控后的 clean data 比对到 Rfam[4] 数据库中的核糖体序列。一般认为 rRNA 含量低于30%为正常,可进行后续分析。比对结果见下表:
表3-2-1 核糖体比对结果(rRNA_stat.tsv)
| SampleID | Total_Reads | mapping_rRNA_Reads | mapping_rRNA_Rate |
|---|---|---|---|
| DRS_0_da_1 | 25705328 | 5035377 | 19.59% |
| DRS_0_da_2 | 26679734 | 6545560 | 24.53% |
| DRS_0_da_3 | 28199738 | 10025230 | 35.55% |
| DRS_4_da_1 | 25567596 | 7612385 | 29.77% |
| DRS_4_da_2 | 24975612 | 9315466 | 37.30% |
| DRS_4_da_3 | 27834176 | 10208429 | 36.68% |
| WT_0_da_1 | 24182292 | 4759388 | 19.68% |
| WT_0_da_2 | 26483202 | 5060237 | 19.11% |
| WT_0_da_3 | 24118702 | 5842252 | 24.22% |
| WT_4_da_1 | 24923920 | 6578523 | 26.39% |
| WT_4_da_2 | 27215978 | 12212712 | 44.87% |
| WT_4_da_3 | 30233108 | 13110873 | 43.37% |
- sampleID: 样本ID
- total_reads:双端 reads 总数
- mapping_rRNA_Reads:基于rfam数据库评估的rRNA reads数
- mapping_rRNA_Rate:基于rfam数据库评估的rRNA百分比
3.2.2 比对参考基因
测序片段是由mRNA随机打断而来,为了确定这些片段对应基因组上的哪些区域,我们使用 bowtie2软件[3]将质控后的clean data reads比对到参考基因组上(参数: 默认参数)。一般要求比对率不低于 70%,比对率过低可能是由于参考物种选择不合适或者参考基因组本身不完善导致。
表3-2-2 各样本序列比对情况汇总(ref_alignment_stat.tsv)
| sampleID | total_reads | Unmapped_mapped(%) | Unique_mapped(%) | Multiple_mapped(%) | Total_Mapped(%) |
|---|---|---|---|---|---|
| DRS_0_da_1 | 25705328 | 75240(0.29%) | 19944342(77.59%) | 5685746(22.12%) | 25630088(99.71%) |
| DRS_0_da_2 | 26679734 | 73868(0.28%) | 19310013(72.37%) | 7295853(27.35%) | 26605866(99.72%) |
| DRS_0_da_3 | 28199738 | 67588(0.24%) | 17479599(61.98%) | 10652551(37.78%) | 28132150(99.76%) |
| DRS_4_da_1 | 25567596 | 98631(0.39%) | 17277473(67.57%) | 8191492(32.04%) | 25468965(99.61%) |
| DRS_4_da_2 | 24975612 | 73744(0.3%) | 15057747(60.29%) | 9844121(39.41%) | 24901868(99.70%) |
| DRS_4_da_3 | 27834176 | 96061(0.35%) | 16968586(60.96%) | 10769529(38.69%) | 27738115(99.65%) |
| WT_0_da_1 | 24182292 | 62061(0.26%) | 18697608(77.32%) | 5422623(22.42%) | 24120231(99.74%) |
| WT_0_da_2 | 26483202 | 71178(0.27%) | 20607707(77.81%) | 5804317(21.92%) | 26412024(99.73%) |
| WT_0_da_3 | 24118702 | 58412(0.24%) | 17610676(73.02%) | 6449614(26.74%) | 24060290(99.76%) |
| WT_4_da_1 | 24923920 | 89475(0.36%) | 17665437(70.88%) | 7169008(28.76%) | 24834445(99.64%) |
| WT_4_da_2 | 27215978 | 86624(0.32%) | 14361519(52.77%) | 12767835(46.91%) | 27129354(99.68%) |
| WT_4_da_3 | 30233108 | 91456(0.3%) | 16504529(54.59%) | 13637123(45.11%) | 30141652(99.70%) |
- sampleID: 样本ID
- total_reads:双端 reads 总数
- Unmapped_mapped(%):没有比对上参考序列的 reads 数
- Unique_mapped(%):在参考序列上有唯一比对位置的测序序列的reads数
- Multiple_mapped(%):在参考序列上有多个比对位置的测序序列的reads数;这部分数据的百分比一般会小于10%
- Total_Mapped(%):比对上参考序列的 reads 总数;一般情况下,如果不存在污染并且参考基因组选择合适的情况下,这部分数据的百分比大于 70%
3.2.3 基因覆盖度分析
以 reads 在参考基因上的分布情况来评价 mRNA 打断的随机程度。由于不同基因有不同的长度,把 reads 在参考基因上的位置标准化到相对位置(reads 在基因上的位置与基因长度的比值*100),然后统计基因的不同位置比对上的 reads 数。如果打断随机性好,reads 在基因各部位应分布得比较均匀。转录本的 测序序列(reads) 实际覆盖度的分布有如下特点:距离转录本的 5'端和 3'端越近,平均测序深度越低,但 总体的均一化程度比较高。
本分析采用 RSeQC 软件[2] 中的geneBody_coverage.py进行分析,参数使用默认参数。
图3-2-1 某个样本序列基因组比对区域分布
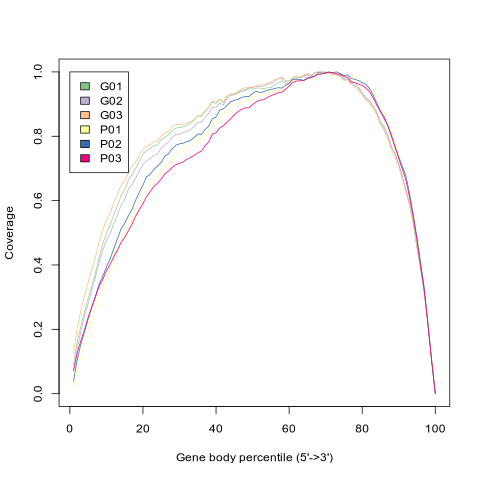
- 图中横坐标为单个基因的碱基长度占总碱基长度的百分比,0表示基因的 5'端,100 表示基因的 3'端;纵坐标为比对到所有基因的横轴位置上相应区间内的序列条数的总和。图中体现了所有基因覆盖情况的叠加结果,曲线中每个点的纵坐标表示所有基因在该相对比例位置上所有序列的数量;曲线反映了测序所得序列是否在基因上均匀分布。如果在靠近左端有明显的峰值,说明测序结果有明显的5'偏向性。如果在靠近右端有明显的峰值,说明测序结果有明显的3'偏向性
3.3 转录本结构分析
03.Structure/ ├── Terminator.csv [终止子详情表] ├── antisense_gene.tsv [反义转录本详情表] ├── gene_operon_length.png [操纵子长度统计图] ├── gene_operon_length.svg [操纵子长度统计图] ├── gene_operon_num.png [操纵子基因数量统计图] ├── gene_operon_num.svg [操纵子基因数量统计图] ├── genome.details.tsv [Rockhopper结果详情表] ├── genome.operons.tsv [操纵子详情表] ├── genome.predicted_RNA_novel_gene.tsv[新转录本预测与注释详情表] ├── genome.transcripts.tsv [转录起始和终止位点预测结果表] └── UTR_detail.tsv [UTR详情表]
3.3.1 操纵子分析
在原核生物的基因组中很多功能相关的基因前后相连成串,由一个共同的控制区进行转录调控,这样的基因结构称为操纵子(operon)。操纵子一般由启动基因、操纵基因和一系列紧密连锁的功能基因组成。
利用软件Rockhopper[5] 获得操纵子预测结果,预测依据主要是基因间的距离信息和表达相关性信息。
图3-3-1-1 操纵子长度统计图

- 图中横坐标为Operon Length,该数值越高,表示操纵子越长纵坐标为操纵子频率,即为对应横轴长度的操纵子总数
图3-3-1-2 操纵子基因数量统计图
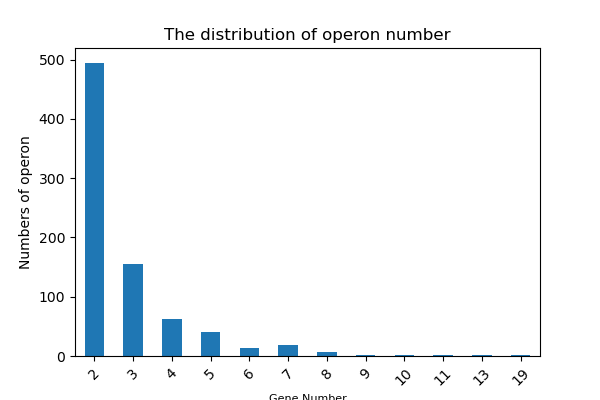
- 图中横坐标为Gene num,该数值越高,表示操纵子包含的基因数越多纵坐标为操纵子频率,即为对应横轴基因数的操纵子总数。
表3-3-1-3 操纵子详情表(genome.operons.tsv)
- seq: 操纵子所在的scaffold名称
- Start:操纵子开始位置
- Stop:操纵子结束位置
- Strand:操纵子所在的链
- Number of Genes:操纵子包含基因个数
- Genes:操纵子包含的基因
- length : 操纵子长度
- group: 操纵子长度分组
3.3.2 转录起始和终止位点预测
转录的起点是指与新生RNA链第一个核苷酸相对应的DNA链上的碱基,研究表明通常为一个嘌呤,即5’UTR的上游第一个碱基。转录终止位点是指当RNA链延伸到此位点时,RNA聚合酶不再形成新的磷酸二酯键,RNA-DNA杂合物分离,转录终止。
利用软件Rockhopper[5] 获得转录起始和终止位点预测结果。
表3-3-2-1 转录起始和终止位点预测结果表(genome.transcripts.tsv)
- seq:基因所在的scaffold名称
- Transcription Start:转录起始位点
- Translation Initiation:翻译起始位点
- Translation Stop:翻译终止位点
- Transcription Terminator:转录终止位点。
- Strand:所在的编码链
- Name:基因名称
- Synonym:基因ID编号
- Product:基因功能描述
3.3.3 UTR注释及分析
UTR(Untranslated Regions)即非翻译区,是mRNA分子两端的非编码片段,包括5’UTR与3’UTR,其中,5’UTR指的是从转录起始位点至起始密码子的一段非翻译区。3’UTR指的是从编码区末端的终止密码子至终止子的一段非翻译区。其在mRNA的稳定性及翻译等生物学过程中发挥着重要的调控作用。
利用软件Rockhopper[5] 获得UTR注释结果。
表3-3-3-1 UTR详情表(UTR_detail.tsv)
- GeneID:基因ID编号
- GeneName:基因名称
- Location:基因所在的scaffold名称
- Strand:操纵子所在的编码链
- Description:基因功能描述
- UTR Start:预测UTR在基因组上的起始位置
- UTR End:预测UTR在基因组上的终止位置
- UTR Length (bp):预测的UTR的长度
- Type:预测UTR的类型,5UTR或3UTR
3.3.4 新转录本预测与注释
用Rockhopper软件将测序结果根据参照参考基因组进行组装,并与NR数据库进行diamond[7]比对(参数:blastx -e 1e-5 -k 1 --more-sensitive) ,发现新的未知转录本区域
表3-3-4-1 新转录本预测与注释详情表(genome.predicted_RNA_novel_gene.tsv)
- new_gene: 新转录本ID
- sseqid: 新转录本注释到 NR 基因 ID
- stitle: 新转录本注释到 NR 基因功能描述
- pident: 比对相似度百分比
- length: 比对长度
- mismatch: 比对不匹配的数量
- gapopen: 比对缺口的数量
- qstart: 新转录本查询起始位置
- qend: 新转录本查询终止位置
- sstart: 注释基因序列起始位置
- send: 注释基因序列终止位置
- evalue: E值
- bitscore: 分数
3.3.5 反义转录本分析
反义转录本(Cis-Natural Antisense Transcripts,cis-NATs)是由源DNA链相同区域转录的内生RNA,与正义转录本存在部分收敛或分散方向的重复。细菌反义转录本功能多样,具有改变目标RNA稳定性 、调控基因表达和蛋白翻译等作用。对于链特异性建库的RNA-seq数据,可以鉴定其反义转录本在基因组上的位置、种类以及数量等。
利用软件Rockhopper[5] 获得反义转录本结果。
表3-3-5-1 反义转录本详情表(antisense_gene.tsv)
- Gene ID(+):正链新转录本ID
- Start(+):正链新转录本的起始位点
- Stop(+):正链新转录本的终止位点
- Description(+):正链新转录本功能描述信息
- Start(-):负链新转录本的起始位点
- Stop(-):负链新转录本的终止位点
- Description(-):负链新转录本功能描述信息
3.3.6 终止子分析
转录进行到一定程度,会停止下来,复合物解体,新生RNA释放出来,称为转录的终止(termination)。终止通常需要一个标志,即终止子(terminator),它是DNA模板上作为转录终止信号的顺式作用元件(cis-acting element)。原核生物有两类终止子:依赖ρ因子的终止子和不依赖ρ因子的终止子。使用TransTermHP[6]软件可以检测原核生物基因组上不依赖ρ因子的终止子。
表3-3-6-1 终止子分析详情表(Terminator.csv)
- GeneID:基因编号
- Gene name:基因名称
- location:基因所在的scaffold名称
- Terminator Start:终止子起始位置
- Terminator End:终止子终止位置
- Strand:基因位于正链或负链
- 5-tail:5'端A尾的碱基序列
- 5-stem:5'端基序序列
- loop:茎环序列
- 3-stem:3'端基序序列
- 3-tail:3'端T尾的碱基序列
- Score:综合"发卡"和"tail"计算的得分值,值越高,结果越可信
3.4 sRNA分析
04.sRNA/ ├── combine_RNAplex_RNAhybrid_result.xls [sRNA注释靶标基因结果] ├── genomic.rfam.final.xls [sRNA注释Rfam数据库结果] ├── sRNA.xls [sRNA预测结果] ├── sRNA.fna [sRNA预测序列] ├── genomic_srna_anno_summary.xls [sRNA注释结果] ├── RNAfold │ ├── RNAfold_stat.txt [sRNA二级结构预测结果表] │ ├── *.pdf [sRNA二级结构图] │ └── *.png [sRNA二级结构图] ├── RNAhybrid_result.xls [sRNA注释靶标基因RNAhybrid结果] ├── RNAplex_result.xls [sRNA注释靶标基因RNAplex结果] ├── sRNA_database_BSRD.xls [sRNA注释BSRD数据库结果] └── sRNATarBase.xls [sRNA注释 sRNATarBase数据库结果]
细菌sRNA是一类长度在50 ~500 nt 的调控小RNA(small RNA, sRNA),通常由基因间区转录而来。细菌sRNA主要通过与靶标 mRNA或靶标蛋白质结合,发挥多种生物学功能。 例如,细菌sRNA在调控外膜蛋白质表达、铁离子平衡、群落感应和细菌致病性等方面发挥重要作用。
利用Rockhopper软件[5] 发现新的基因间区转录本,通过diamond blastx与nr库作比对,对新预测的转录本区域进行注释,将注释不上的转录本且长度适宜的作为候选的非编码sRNA。然后,通过RNAfold软件进行二级结构预测,并使用RNAplot软件对二级结构进行可视化展示。
3.4.1 sRNA预测
根据当前主流的原核转录组分析软件Rockhopper获得sRNA预测结果,预测依据主要是碱基测序覆盖度信息。
表3-4-1 sRNA预测结果(sRNA.xls)
- name: sRNA ID
- chr : sRNA染色体位置
- start:sRNA开始位置
- end:sRNA结束位置
- strand:sRNA所在的链
3.4.2 sRNA注释
利用 Blast 及公共数据库sRNATarBase [11],BSRD [12]及 Rfam [4] 对鉴定到的 sRNA 进行注释。
表3-4-2 sRNA注释结果(genomic_srna_anno_summary.xls)
- sRNA ID: sRNA 编号
- Rfam,sRNATarBase,BSRD:依次为比对上Rfam,sRNATarBase,BSRD数据库
3.4.3 sRNA二级结构预测
RNA 的二级结构除了维持 RNA 本身的稳定性之外,其也可以参与一些基因的调控作用。因此了解一个 RNA 的二级结构还是十分重要的。本研究使用了ViennaRNA [9] 中的 RNAfold模块进行预测sRNA结构。
表3-4-3 sRNA二级结构预测结果表(RNAfold_stat.txt)
- sRNA ID: sRNA 编号
- MFE Structure in Ensemble:MFE即minimum free energy,二级结构的最小自由能量值
- Ensemble Diversity:二级结构的多样性
3.4.4 sRNA靶标预测
sRNA大多数是通过对其靶基因配对结合后行使调控功能,sRNA的功能研究其实就是对靶基因的功能研究。一个sRNA可能靶向多个mRNA,同一靶基因也可能受到多个不同种类的sRNA调控。我们对主要的sRNA即反式编码作用的sRNA(trans-encoded sRNA)进行靶基因预测。研究表明,trans-encoded sRNA多结合到mRNA的5'UTR或AUG附近的序列,抑制靶mRNA翻译。本分析利用常见的靶基因预测软件对所有已知及新预测的trans-encoded sRNA的靶基因进行预测,并对靶基因进行功能描述。
根据sRNA序列和二级结构预测结果,利用RNAhybrid[10] 和RNAplex[8] 软件对sRNA靶标进行预测。
表3-4-4 sRNA靶标基因预测结果表(combine_RNAplex_RNAhybrid_result.xls)
- sRNA ID: sRNA 编号
- Target Gene ID:sRNA靶基因ID编号
- Database:预测工具
- Gene Symbol:sRNA靶基因名称
- description:sRNA靶基因功能描述
3.5 变异位点分析
04.SNP/ ├── * │ ├── *.gff [GFF3格式的变异] │ ├── *.tab [所有变异的结果表] │ ├── *.txt [所有变异的结果表摘要] │ ├── *.vcf [最终注释的VCF格式变异] │ └── *.vcf.gz [VCF格式变异压缩格式] └── all_snp.tsv [snp汇总结果]
SNP(Single Nucleotide Polymorphisms,单核苷酸多态性),是指碱基序列上单个核苷酸的变异,包括置换、颠换。InDel(Insertion/Deletion ), 是指碱基序列上小片段的插入和缺失.
变异位点分析是RNA-Seq结构分析的重要内容,本分析采用snippy软件[13] 进行变异位点的检测和分析.
表3-5-1 snp预测结果表(all_snp.txt)
- CHROM:变异所在的序列,例如FASTA参考中>后面的名称
- POS:从1开始计数的序列中的位置
- TYPE:变异类型:snp msp ins del complex
- REF:参考中的核苷酸(s)
- ALT:读取支持的备用核苷酸(s)
- FTYPE: 受影响特征的类别:CDS tRNA rRNA ...
- STRAND:所在编码链
- NT_POS:变异在特征内的核苷酸位置 / 核苷酸长度
- AA_POS:残基位置 / 氨基酸长度(仅当FTYPE为CDS时)
- EFFECT:此变异的snpEff注释后果(.vcf中的ANN标签)
- LOCUS_TAG:locus_tag(如果存在)
- GENE:基因
- PRODUCT:产物
- tran_type:类型
- *_all_read:样本在该SNP/InDel位点的测序深度;
- *_alt_read:样本在该SNP/InDel位点的突变个数;
- *_mapping_rate:样本在该SNP/InDel位点的突变率,范围0~1.
3.6 定量分析
06.Quant/
├── CountsQC [qualimap Counts QC报告]
│ ├── [样本]Report.html [单个样本的报告]
│ ├── GlobalReport.html [所有样本的总报告]
| └── * [报告数据和图片]
├── gene_count.xls [基因比对到的reads数矩阵]
├── gene_deseq2.xls [用DESeq2的方法校正后的表达量矩阵]
├── gene_edger_TMM.xls [用edgeR的方法校正后的表达量矩阵]
├── gene_fpkm.xls [FPKM表达量矩阵]
├── gene_tpm.xls [TPM表达量矩阵]
├── boxplot
│ ├── Category_boxplot.svg [TPM表达量分布箱线图]
│ └── Category_data_matrix.xls [箱线图数据]
├── heatmap
│ ├── [分组方案]_correlation_heatmap.svg [TPM表达量样本间spearman相关性热图]
│ ├── [分组方案]_correlation_matrix.xls [TPM表达量样本间spearman相关系数矩阵]
│ ├── [分组方案]_p_value_matrix.xls [TPM表达量样本间spearman相关系数p值矩阵]
├── pca
│ ├── [分组方案]_PCA_3D.svg [TPM表达量3D PCA图]
│ ├── [分组方案]_pca_points_ordinates.xls [PCA各样本坐标]
│ └── [分组方案]_PCA.svg [TPM表达量PCA图]
└── violin
├── [分组方案]_data_matrix.xls [小提琴图数据]
└── [分组方案]_violin.svg [TPM表达量分布小提琴图]
用subRead软件包中的featureCounts软件[14]计算gene count(gene_count.xls), 关键计算参数为: -p -t exon -g gene_id。这里的count指的是fragment count,即一对reads是按照一个整体(fragment)来计数的。
FPKM和TPM的计算请参照文献中的公式,这两个表达量可用于比较样本或分组之间的表达量差异,也能用于比较基因之间的表达量差异。
以gene_count.xls为输入,筛除检出率(count不为0的比例)小于0.25的基因, 用R语言DESeq2包[15]和edgeR包[16] 分别计算校正后的表达量gene_deseq2.xls和gene_edger_TMM.xls;这两个表达量表格可用于比较样本或分组之间的表达量差异,但不能用于比较基因之间的表达量差异。 请注意,这个两个文件并不能作为DESeq2和edgeR的直接输入文件,也不能用于计算DESeq2和edgeR的FoldChange,DESeq2和edgeR只能用gene_count.xls作为输入文件。
3.6.2 基因表达分布
为展示各个样本的基因表达量的整体的分布情况,我们对所有样本的所有基因的TPM值,用R语言程序作“小提琴图”和“箱线图”。为避免图中数据点的跨度太大,我们对TPM值,做了log2(TPM+1)的缩小变换处理。
箱线图可以展示样本基因表达量分布情况:

图3-6-2 基因表达分布箱线图
箱子下,中,上沿分别对应,下四分位点,中位数,上四分位点,竖线标明了±3倍标准差的范围
小提琴图也可用于展示样本基因表达量分布情况:

图3-6-3 基因表达分布小提琴图
小提图琴是个密度图,越宽的地方说明对应于纵轴表达量的基因越多。
3.6.3 样本间相关性
用样本的TPM或FPKM数据计算两两样本间的相关性系数,通过观察相关性系数的大小,可以大致评估样本组内的生物学实验重复性如何。数据只保留了在本分组方案中,在所有的样本中的TPM之和大于0的基因,而把完全不表达的基因的信息给略去了。
Encyclopedia of DNA Elements (ENCODE) Consortium,是由美国国家人类基因组研究所(NHGRI)资助的,一个国际合作研究小组。ENCODE的目标是构建人类基因组功能元件的信息,包括在蛋白质和RNA水平上起作用的元件,以及控制细胞和基因活动环境的调控元件。
ENCODE project 2016年的RNA-Seq指导方案中写到,样本间相关系数要在0.9 或0.8以上:
- 对于来自同一个人体供体(或者同一个模式生物菌株)的生物学重复样本,要求在0.9以上;
- 对于来自不同的人体供体(或者模式生物不同的菌株)的相近的组织的生物学重复样本,要求在0.8以上。

图3-6-4 TPM表达量样本间spearman相关性热图
热图中的单元格颜色越深,表示对应的两个样本之间的相关性系数越高。同一个小组内的样本应该具有较高的相关性系数。同一个小组内的样本应该具有较高的相关性系数。
3.6.4 主成分分析
主成分分析(PCA)也常用来评估组间差异及组内样本重复情况,PCA采用线性代数的计算方法,对数以万计的基因变量进行降维及主成分提取。我们对所有样本的基因表达值(TPM)进行PCA分析,如下图所示。理想条件下,PCA图中,组间样本应该分散,组内样本应该聚在一起

图3-6-5 主成分分析结果图
图中横坐标为第一主成分,纵坐标为第二主成分,不同的颜色表示不同的分组。样本点之间的距离近似于样本之间各基因TPM差异的总和
3.7 挑选差异表达基因
07.DEG/ ├── [分组方案]_[处理组].vs.[对照组] │ ├── [分组方案]_[处理组].vs.[对照组]_All_KEGG.xls [KEGG基因差异分析的完整结果,用于下游KEGG GSEA分析] │ ├── [分组方案]_[处理组].vs.[对照组]_All.xls [基因差异分析的完整结果,用于下游GO GSEA分析] │ ├── [分组方案]_[处理组].vs.[对照组]_DEG_KEGG.xls [显著差异的KEGG基因集,用于下游KEGG ORA分析] │ ├── [分组方案]_[处理组].vs.[对照组]_DEG_STRING.xls [显著差异的STRING基因集,用于下游PPI(蛋白互作网络)分析] │ ├── [分组方案]_[处理组].vs.[对照组]_DEG.xls [显著差异的基因集,用于下游GO ORA分析,Venn|upset图,聚类热图] │ ├── [分组方案]_[处理组].vs.[对照组]_Volcano.svg [差异分析火山图] │ ├── heatmap.svg [差异最显著的基因表达量聚类热图] │ ├── input.xls [聚类热图输入表达量矩阵] │ └── table.xls [聚类热图最终数据] └── VennUpSet ├── DEG_upset.svg [各差异基因集之间的UpSet图] ├── DEG_upset_venn_intersects.xls [各差异基因集之间的交集] ├── DEG_venn.svg [各差异基因集之间的Venn图] ├── summary_up_down.svg [各差异基因集上调,下调数目汇总柱形图] └── summary_up_down.xls [各差异基因集上调,下调数目汇总表]
在转录组中,确定某个基因在不同的样品中的表达量是否有差异是分析的核心内容之一。获得基因表达量后,即可对表达数据进行统计学分析,进而筛选不同样本之间显著差异的基因。差异分析主要分为四个步骤:
- 以gene_count.xls为输入,筛除检出率(count不为0的比例)小于0.25的基因,这些基因通常不服从分析模型的数据分布假设,因而不适合做差异分析
- 对count进行标准化(normalization),主要是对测序深度的校正
- 通过统计学模型进行假设检验,计算p value
- 进行多重假设检验校正(BH方法),获得经校正的p value(结果表中的padj值:校正的p value)
针对不同的实验情况,我们选用合适的软件进行基因表达差异显著性分析, 具体如下表所示:
表3-7-1 表达差异分析所用软件
| 类型 | R语言包 | 标准化方法 | 数据分布假设 | pvalue计算模型 | padj计算方法 |
|---|---|---|---|---|---|
| 有生物学重复 | DESeq2[15] | DESeq2 | 负二项分布 | 广义线性模型 | BH |
| 无生物学重复 | edgeR[16] | TMM | 负二项分布 | 广义线性模型 | BH |
一般来说,如果一个基因在两组样品中的表达量差异达到两倍以上,我们认为这样的基因是具有表达差异的。为了判断两个样品之间的表达量差异究竟是由于各种误差导致的还是本质差异,我们需要对所有基因在这两个样本中的表达量数据进行假设检验。而转录组分析是针对成千上万个基因进行的,这样会导致假阳性的累积,基因数目越多,假设检验的假阳性累积程度会越高,所以引入padj对假设检验的 P-value 进行校正,从而控制假阳性的比例。
差异基因的筛选标准是非常重要的,我们给出的标准|log 2 (FoldChange)| > 1 &padj< 0.05是常用的经验值,也是我们分析流程的默认值。在实际项目中可以根据情况灵活选择,例如,差异倍数可以选择 1.5 倍,也可以选择 3 倍,padj 常用的阈值包括 0.01、0.05、0.1等。若按照以上标准筛选得到的差异基因过少,很有可能导致后面的功能富集分析没有显著性结果。若项目实验只关注某几个基因的表达情况(如基因敲除), 不在意富集结果,从下面的差异分析表格中筛选关注的那几个基因即可。反之,如果得到的差异基因数目过多,不利于后续目标基因的筛选,这个时候可使用更严格的阈值标准进行筛选。生科云的云流程提供了调整筛选阈值的途径。
结果文件夹中,[分组方案]_[处理组].vs.[对照组]_*.xls表格文件的各字段解释如下
- Features: 基因ID
- log2FoldChange: 处理组与对照组基因表达水平的比值,再经过差异分析软件收缩模型处理,最后以 2 为底取对数
- logCPM: edgeR结果特有,log2(所有样本校正后表达量均值)
- LR: edgeR结果特有,检验统计量,用于计算p值,无需关注
- baseMean: DESeq2结果特有,所有样本校正后表达量均值
- pvalue: 显著性检验的p值
- padj: BH方法校正后的p值
- -log10(pvalue): -log10(pvalue)
- -log10(padj): -log10(padj)
- KEGG Gene ID: KEGG数据库对应的基因ID
- GO: GO数据库对应的基因本体条目
- STRING Protein: STRING数据库对应的蛋白ID
- Gene Symbol: 基因名
- TF Family: 基因转录因子家族注释
- description: 基因功能描述
火山图同时展示了差异分析的-log10(pvalue)和log2FoldChange

图3-7-1 差异分析火山图
标出基因名的是差异显著且padj最小的基因
summary_up_down.svg汇总了各差异基因集上调(处理组表达量高于对照组),下调数目

图3-7-2 各差异基因集上调,下调数目汇总柱形图
如果有多个比较方案,多个差异基因集,我们将用Venn图和UpSet图(DEG_venn.svg|图3-7-3,DEG_upset.svg|图3-7-4)展示各个差异基因集之间的交集大小(共有的差异基因数目),以及各个差异基因集特有的差异基因。Venn图和UpSet图表达的信息是一样的,只是用了不同的数据可视化形式。Venn图最多能展示五个差异基因集的关系,而UpSet图能展示的差异基因集个数能够更多。

图3-7-3 各差异基因集之间的Venn图

图3-7-4 各差异基因集之间的UpSet图
差异基因聚类热图(heatmap.svg,图3-7-5)展示了最显著的(padj最小)的基因的表达量矩阵。为了与p值计算方法保持一致,对于没有生物学重复的比较方案,我们用6.Quant/gene_edger_TMM.xls作为输入,有生物学重复则用6.Quant/gene_deseq2.xls。为了保证图片的可读性,我们展示的基因不会超过20个(云流程可调整)

图3-7-5 差异最显著的基因聚类热图
图中用颜色代表表达量,数据跨度太大会导致差异无法区分,我们对表达量进行标准化处理(减去平均值,除以标准差);聚类到一起的样本表达模式比较接近
3.8 富集分析
08.Enrich
├── GSEA
│ ├── GO
│ │ └── [分组方案]_[处理组].vs.[对照组]
│ │ ├── circular_cnetplot.svg [富集分析p值(p.adjust)最小的条目的环状基因概念网络]
│ │ ├── cnetplot.svg [富集分析p值(p.adjust)最小的条目的基因概念网络]
│ │ ├── dotplot.svg [富集分析p值(p.adjust)最小的条目的气泡图]
│ │ ├── emapplot.svg [富集分析p值(p.adjust)最小的条目的emapplot]
│ │ ├── enrich.xls [富集分析结果表格]
│ │ ├── heatplot.svg [富集分析p值(p.adjust)最小的条目的基因概念瀑布图]
│ │ ├── summary_gseaplot.svg [富集分析p值(p.adjust)最小的条目的gseaplot]
│ │ └── treeplot.svg [富集分析p值(p.adjust)最小的条目的聚类树图]
│ └── KEGG
│ └── [分组方案]_[处理组].vs.[对照组]
│ ├── circular_cnetplot.svg
│ ├── cnetplot.svg
│ ├── dotplot.svg
│ ├── emapplot.svg
│ ├── enrich.xls
│ ├── heatplot.svg
│ ├── KEGG_pathview [包含富集分析p值(p.adjust)最小的KEGG通路的通路图的文件夹]
│ ├── summary_gseaplot.svg
│ └── treeplot.svg
└── ORA
├── GO
│ └── [分组方案]_[处理组].vs.[对照组]
│ ├── circular_cnetplot.svg
│ ├── cnetplot.svg
│ ├── dotplot.svg
│ ├── emapplot.svg
│ ├── enrich.xls
│ ├── heatplot.svg
│ └── treeplot.svg
└── KEGG
└── [分组方案]_[处理组].vs.[对照组]
├── circular_cnetplot.svg
├── cnetplot.svg
├── dotplot.svg
├── emapplot.svg
├── enrich.xls
├── heatplot.svg
├── KEGG_pathview
└── treeplot.svg
注: 同名文件解释相同,不赘述
本报告所有富集分析使用的都是R语言clusterProfiler包[19]。
关于本报告中使用的富集分析的详细介绍,请参考clusterProfiler包教程
对于KEGG富集分析,参考基因组基因结构注释文件中使用的基因ID,和KEGG数据库使用基因ID是不一样的,在进行KEGG通路富集前,我们需要将参考基因组基因ID转换为KEGG数据库使用的基因ID。如果KEGG数据库存在该物种基因ID与参考基因组基因ID的对应关系,我们可以直接匹配。但大部分非模式物种不存在这种匹配关系,在这种情况下,我们就用emapper软件通过序列比对寻找KEGG数据库的直系同源基因组(KEGG Orthology, K+数字,如K00010),用于KEGG富集分析。无论哪种ID转换方式,都有相当一部分基因无法找到匹配记录,从而无法参与富集分析
GO富集分析的情况也类似。在进行GO富集分析之前,我们需要知道每个基因属于哪些GO条目。当NCBI数据库存在该物种的基因与GO条目的对应关系时,我们可以直接匹配。但大部分非模式物种不存在这种匹配关系,在这种情况下,我们就用emapper软件通过序列比对寻找匹配的GO条目
为了保证结果图的可读性,cnetplot.svg, heatplot.svg,gseaplot.svg图选取最显著的(p.adjust最小)5个条目作图。dotplot.svg, treeplot.svg, emapplot.svg图选取最显著的20个条目作图。云流程可自由调整
ORA分析
在上游分析得到了组间表达量有显著性差异的基因数据后,我们可以在基因注释文件中查到单个基因的功能。此外,我们还可以探究这些具有研究意义的基因中,是否显著地对应着一些功能分类的基因的集合,从而推断差异表达基因主要参与的生物学过程
KEGG代谢通路数据库中,有很多前人归纳的生物的代谢通路,一个代谢通路包含了一定数量的基因,那么我们得到的差异表达的基因集合中,会不会存在一种情况,即大量的基因集中出现在一个或几个代谢通路中,如果是这样,那么不同处理所影响的生物学过程就更加明确了。类似的,常见的功能富集分析还有GO条目富集分析。
ORA分析结果表格(ORA/[KEGG|GO]/enrich.xls)各列含义如下
- ID: 富集到的条目(如KEGG通路)的ID
- Description: 富集到的条目(如KEGG通路)的描述
- GeneRatio: 匹配到该条目的差异基因数/差异基因总数
- BgRatio: 该条目一共有多少基因/所有条目一共有多少基因
- pvalue: 显著性检验p值
- p.adjust: BH方法校正后的p值
- qvalue: 校正错误发现率(FDR)的p值
- geneID: 与该条目相匹配的差异基因ID或基因名
- Count: 匹配到该条目的差异基因数
围绕该结果表格,我们做了很多可视化。
GO ORA

图3-8-1 富集分析p值(p.adjust)最小的条目的气泡图(dotplot.svg)
点大小对应Count: 匹配到该条目的差异基因数,即enrich.xls表Count列(ORA结果)或者core_enrichment列基因个数(GSEA结果);颜色对应p.adjust; BH方法校正后的p值; 横坐标对应GeneRatio:匹配到该条目的差异基因数/差异基因总数

图3-8-2 富集分析p值(p.adjust)最小的条目的基因概念网(cnetplot.svg)
图中,每一簇的节点的中心是GO条目,这些外围的节点是对应的基因(即enrich.xls表geneID列(ORA分析)或者core_enrichment列(GSEA分析)),有一些基因可能会同时拥有多种GO条目的功能描述。 图中右侧的图例,size表示某一个GO条目对应有多少个基因(即enrich.xls表Count列(ORA结果)或者core_enrichment列基因个数(GSEA结果)),在作图区中表现为,一个GO条目对应的基因个数越多,则该GO条目的圆点越大;而所有的基因节点的面积大小是相同的,这些节点没有表征个数多少的含义; 图中右侧的图例,fold change,它指的是上游的差异分析中,得到的在某个比较组合中每一个基因的log2FoldChange值,作图区中的基因的节点的颜色跟log2FoldChange值是直接对应的;而中心的GO条目圆点的颜色都是相同的,它们的颜色不表征log2FoldChange值的含义; 给线条涂了不同的颜色,使得不同的GO条目延伸出来的线条颜色是不同的;

图3-8-3 网络富集分析p值(p.adjust)最小的条目的环状基因概念网络(circular_cnetplot.svg)
circular_cnetplot.svg是前面的cnetplot.svg的一种特殊画法,图中元素的内容本质上是一样的, 只是把所有的基因节点与GO条目圆点都尽量画在一个圆周上。

图3-8-4 富集分析p值(p.adjust)最小的条目的基因概念瀑布图(heatplot.svg)
这个热图是非聚类热图,表达的意思和cnetplot.svg相似。横轴代表基因,按照英文字母从A到Z的顺序,把基因从左到右排列;纵轴代表GO条目,按照英文字母从A到Z的顺序,把GO条目从下往上排列。 图中右侧的图例,fold change,它指的是上游的差异分析中,得到的在某个比较组合中每一个基因的log2FoldChange值,作图区中的基因对应的单元格的颜色跟log2FoldChange值是有关联的。由于log2FoldChange只跟基因有关,而与GO条目无关,所以在横轴的某一个基因的上方,如果出现了多个有颜色的单元格,那么它们的颜色应该是相同的;而如果在某个位置没有出现涂色的单元格,则表示enrich.xls表中在纵轴坐标对应的GO条目的geneID列(ORA分析)或者core_enrichment列(GSEA分析)中不包含横轴对应的这个基因。
KEGG ORA
除上文介绍的富集结果图外,KEGG ORA在KEGG_pathview文件夹中还有最显著的通路图。
图3-8-5 富集分析p值(p.adjust)最小的KEGG通路的通路图
图中红色表示上调基因,绿色表示下调基因。鼠标悬停于标记节点,可弹出差异基因的细节信息,主要包括基因 ID, log2FoldChange和 padj 值。 点击各个节点,可以连接到 KEGG 官方数据库中各个节点的具体信息页。
GSEA分析
ORA分析关注的是差异表达基因,然而可能筛不到差异表达基因。GSEA可以用所有基因参与分析,GSEA在一个基因集(如某个GO条目或者KEGG通路)中累加计算一个统计量,因此可以用于检测一些协同作用的小效应,这很重要,因为很多表型差异是由很多协同作用的小效应造成的。
给定一个预先定义的基因集S(如一个GO条目的成员基因集),和一个依据某个指标排好序的基因列表L(本报告中L采用所有基因的log2FoldChange排序),GSEA的目的在于检验S的成员是随机分散在L中(p.adjust>0.05),还是主要集中在L的底部或者顶部(p.adjust<0.05); 在本报告中,enrich.xls中的p.adjust<0.05也就意味着对应富集条目(如某个GO条目或者KEGG通路)的大部分成员基因低表达,或者高表达
除上文介绍的富集结果图外,GSEA分析还有一个专门为其量身打造的GSEA图
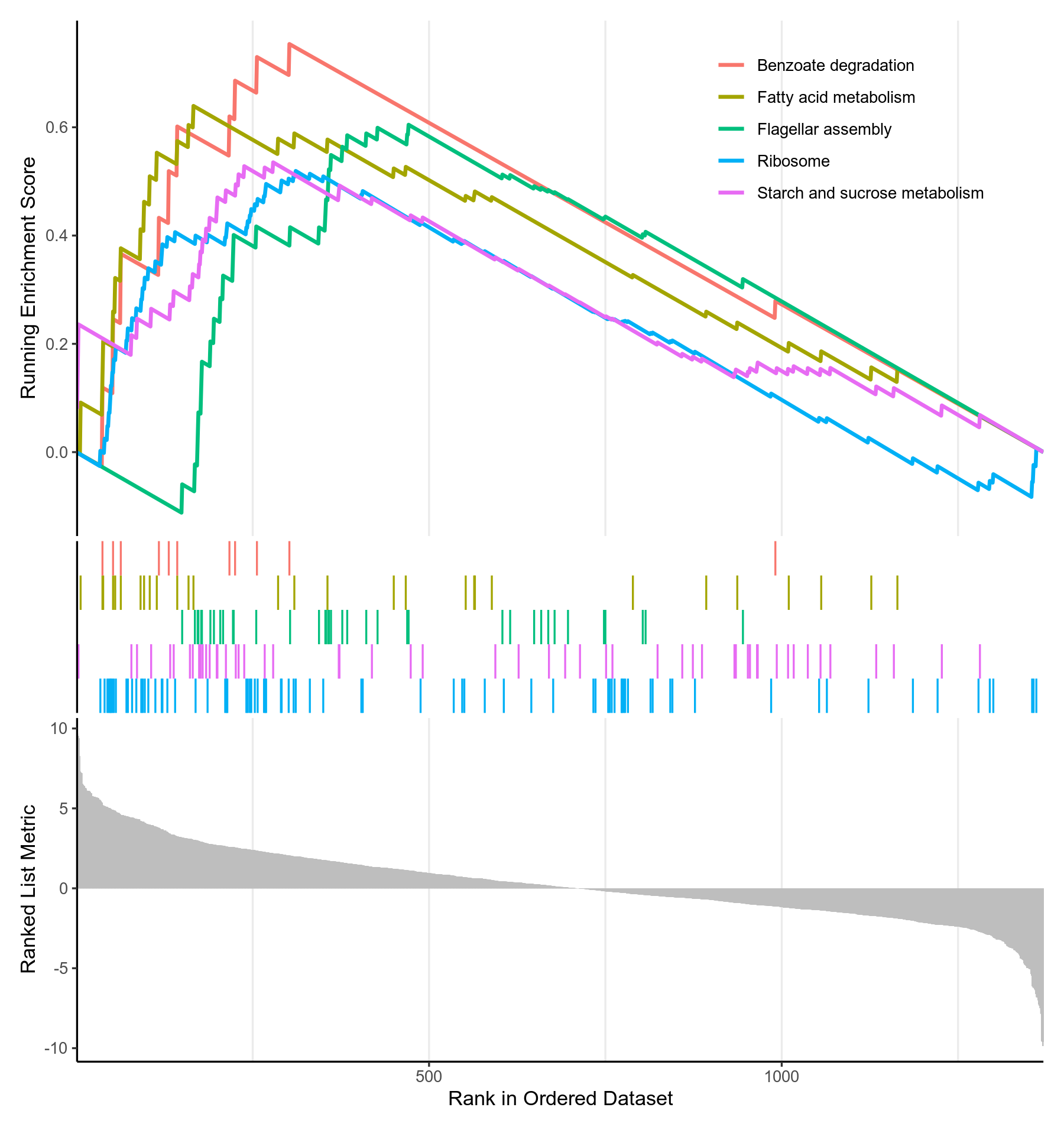
图3-8-6 GSEA富集分析p值(p.adjust)最小的KEGG通路的gseaplot
- 该图分为三部分。横坐标都代表排好序的基因列表L,如1代表log2FoldChange最高的基因。
- 对于上部分:纵坐标Running Enrichment Score的计算方式如下:从基因集L的第一个基因开始,计算一个累计统计值。当遇到一个落在S里面的基因,则增加统计值。遇到一个不在S里面的基因,则降低统计值。如果S的成员是随机分散在L中,则对应基因集的线(某个KEGG通路的线,一种颜色代表一个KEGG通路)应该是平缓的。如果存在一个单峰,则表示大部分S的成员聚集在峰的区域(不包含峰后面的部分),该区域的基因即enrich.xls的core_enrichment列(S的子集),该单峰的纵坐标即为富集得分(enrich.xls的enrichmentScore),横坐标即为enrich.xls的rank列
- 中间部分用竖线代表S的成员(某个KEGG通路的成员),有竖线,代表S包含该基因(KEGG通路包含该基因),竖线密集的地方就是Running Enrichment Score峰值出现的部位,每种颜色代表一个单独的S(KEGG通路)
- 下部分展示了排好序的基因列表L的排序指标,这里的纵坐标就是log2FoldChange
GSEA分析的enrich.xls的各列解释如下:
- ID: 富集到的条目(如KEGG通路)的ID
- Description: 富集到的条目(如KEGG通路)的描述
- setSize: 富集到的条目(如KEGG通路)的所有成员基因个数
- enrichmentScore: 富集分数
- NES: 标准化富集分数,GSEA的关键统计量,用于计算p值(置换检验)
- pvalue: 显著性检验p值(置换检验)
- p.adjust: 校正后p值(BH方法)
- qvalues: 校正后p值(FDR方法)
- rank: Running Enrichment Score达到最高值的排序位置(图3-8-6对应峰值的横坐标)
- leading_edge: 这些指标是用来表征core_enrichment(S的子基因集)的算法度量,无需关注。实在好奇,请参考GSEA官方解释
- core_enrichment: 核心富集基因集,即enrichmentScore峰值往前的S的子基因集
语义相似性分析
富集结果中的emapplot.svg和treeplot.svg是富集条目之间语义相似性分析结果图,这里使用的相似性指数是Jaccard correlation coefficient,计算公式如下:
即两个富集条目所包含基因集合[enrich.xls表geneID列(ORA分析)或者core_enrichment列(GSEA分析)]的交集基因数除以并集基因数

图3-8-7 富集分析p值(p.adjust)最小的条目的emapplot(emapplot.svg)
- 节点的大小对应enrich.xls的Count列(ORA结果)或者core_enrichment列基因个数(GSEA结果)
- 节点的颜色对应enrich.xls的p.adjust列
- 节点之间的连线代表Jaccard correlation coefficient。可理解为连线越粗,两个条目共有的基因个数(标准化后)越多

图3-8-8 富集分析p值(p.adjust)最小的条目的聚类树图(treeplot.svg)
- 节点的大小对应enrich.xls的Count列(ORA结果)或者core_enrichment列基因个数(GSEA结果)
- 节点的颜色对应enrich.xls的p.adjust列
- 这是一个依据条目之间Jaccard correlation coefficient进行聚类的树图,聚到一起的条目之间的Jaccard correlation coefficient较大,即共有基因数较多。每种颜色代表一个聚类,从聚类中随机挑选一个单词(通常是聚类中词频比较高的单词)作为该聚类的名称写在右边。
3.9 蛋白互作网络分析
09.PPI/ ├── [分组方案]_[处理组].vs.[对照组] │ ├── edges.xls [网络边(连线)数据] │ ├── network.html [差异基因的蛋白互作网络图,可动态调整网络] │ └── nodes.xls [网络节点(蛋白)数据]
该分析主要是从STRING数据库[20]搜索差异表达基因对应蛋白的互作网络,用网络图展示。
进行该分析时,我们需要将参考基因组的基因ID与STRING数据库的蛋白ID匹配,如果STRING数据库存在对应物种的ID匹配关系,我们可以直接匹配。但大部分非模式物种不存在这种匹配关系,这时候,我们用emapper软件寻找参考基因组的蛋白的直系同源蛋白簇(COGs, KOGs),用于蛋白互作网络分析
为了保证网络的可读性,我们对网络做如下筛选
- 初步筛选可信度(combined_score)最高的前1000个互作关系
- 最终筛选连接度(degree)最高的5个节点(关键基因|蛋白),以及与之互作的节点
这些筛选阈值可在云流程调整
图3-9-1 差异基因的蛋白互作网络图
为了提升交互体验,可打开一个新的网页操作网络
网络边(连线)数据(edges.xls)各列解释如下:
- protein1: 某个互作关系的第一个蛋白ID
- protein2: 某个互作关系的第二个蛋白ID
- database: 数据库注释的蛋白互作可信度
- database_transferred: 从其他物种(依据同源性)推断的database
- experiments: 实验验证的蛋白互作可信度
- experiments_transferred: 从其他物种(依据同源性)推断的experiments
- coexpression: 共表达可信度
- coexpression_transferred: 从其他物种(依据同源性)推断的共表达可信度
- textmining: 文献报道的蛋白互作可信度
- textmining_transferred: 从其他物种(依据同源性)推断的textmining
- fusion: 存在基因融合的可信度
- neighborhood: 染色体上距离较近的可信度
- neighborhood_transferred: 从其他物种(依据同源性)推断的neighborhood
- cooccurence: 共现性可信度
- combined_score: 综合计算后蛋白互作可信度
网络节点(蛋白)数据(nodes.xls)各列解释如下:
- nodes: 互作的节点ID,对应edges.xls的protein1和protein2
- Gene ID: 基因ID
- Gene Symbol: 基因名
- preferred_name: STRING数据库提供的节点名
- protein_size: 蛋白分子量
- annotation: 蛋白描述
- log2FoldChange: 差异分析中的log2FoldChange
- -log10(padj): 差异分析中的-log10(padj)
- up_down: 差异分析中是上调(up)还是下调(down)
- absolute(log2FoldChange): log2FoldChange绝对值
3.10 WGCNA分析
10.WGCNA/
├── 1.Modules [鉴定模块文件夹]
│ ├── [模块名]_genes_KEGG.xls [某个模块内的KEGG基因,用于下游KEGG富集分析]
│ ├── [模块名]_genes.xls [某个模块内的基因,用于下游GO富集分析]
│ ├── input_batch_effect_removed.xls [去除批次效应后的输入文件]
│ ├── mean_connectivity.svg [去除批次效应后的输入文件]
│ ├── model_fit.svg [不同power(幂次)下拓扑模型的拟合度]
│ ├── modules_dendrogram_power[模型所用power].svg [模块基因聚类树]
│ └── modules_ME.xls [Module eigengene E矩阵(可理解为模块表达量)]
├── 2.Network
│ ├── edges.xls [拓扑重叠网络边数据]
│ ├── network.html [交互式拓扑重叠网络]
│ └── nodes.xls [拓扑重叠网络节点数据]
├── 3.Enrich
│ ├── GO
│ │ ├── [模块名] [对应模块GO富集分析(ORA)结果]
│ │ └── *
│ └── KEGG
│ ├── [模块名] [对应模块KEGG富集分析(ORA)结果]
│ └── *
└── 4.Correlation
├── correlation_heatmap.svg [模块与表型的相关性热图]
├── correlation_matrix.xls [模块与表型的相关系数(pearson)矩阵]
└── pvalue_matrix.xls [模块与表型的相关系数p值矩阵]
加权基因共表达网络分析 (WGCNA, Weighted correlation network analysis)是用来描述不同样品之间基因关联模式的系统生物学方法,可以用来鉴定高度协同变化的基因集, 并根据基因集的内连性和基因集与表型之间的关联鉴定候补生物标记基因或治疗靶点。
相比于只关注差异表达的基因,WGCNA利用全部基因的信息识别感兴趣的基因集,并与表型进行显著性关联分析。一是充分利用了信息,二是把数千个基因与表型的关联转换为数个基因集与表型的关联,免去了多重假设检验校正的问题。
共表达网络定义为加权基因网络。点代表基因,边代表基因表达相关性。加权是指对相关性值进行幂次运算(幂次的值也就是软阈值 (power, model_fit.svg展示了确定合适的power的过程))。无符号(unsigned)网络的边属性计算方式为abs(cor(genex, geney)) ^ power;有符号(signed)网络的边属性计算方式为(1+cor(genex, geney)/2) ^ power; sign hybrid的边属性计算方式为cor(genex, geney)^power if cor>0 else 0。这种处理方式强化了强相关,弱化了弱相关或负相关,使得相关性数值更符合无标度网络特征,更具有生物意义。
WGCNA分析将共表达网络转换为TOM拓扑重叠矩阵 (Topological overlap matrix),以降低噪音和假相关,获得的新距离矩阵。当两个基因在共表达网络中拥有较多相同的"邻居"时,我们说这两个基因拓扑重叠
WGCNA分析利用TOM拓扑重叠矩阵对基因进行聚类,将拓扑重叠的基因聚为一个模块。Module(模块)指的是高度內连的基因集。在无符号(unsigned)网络中,模块内是高度相关的基因。在有符号网络中,模块内是高度正相关的基因。把基因聚类成模块后,我们对每个模块进行两个层次的分析:1. 功能富集分析查看其功能特征是否与研究目的相符;2. 模块与性状进行关联分析,找出与关注性状相关度最高的模块
鉴定模块
WGCNA相关分析使用R语言WGCNA包[21]完成。我们默认以gene_deseq2.xls作为输入文件,计算pearson相关系数,用有符号(signed)的方式加权以构建共表达网络,,进而鉴定模块。
图3-10-1展示了不同power(幂次)下,WGCNA拓扑模型的拟合度,拟合度绝对值高于0.85时的power作为最终加权幂次(所选power在文件名modules_dendrogram_power%s.svg中)。

图3-10-1 不同power(幂次)下拓扑模型的拟合度
图3-10-2展示了不同power(幂次)下,加权共表达网络中基因的平均连接度。连接度太高,不利于模块的区分,可能导致最终结果里只有一个模块,发生这种现象的原因主要有三个:
- 有离群样本
- 各分组间样本差异太大(批次效应)
- 样本数太少。样本少时,基因之间倾向于有较高的相关系数值。举个极端例子,当只有两个样本时,任意两个基因之间的相关系数都是1,无论怎么分,只可能有一个模块。通常样本数多于15个时,才能有较好的模块鉴定结果。

图3-10-2 不同power(幂次)下基因平均连接度
modules_ME.xls文件中给出了每个模块的基因成员(最后一列),以及它在各个样本的Module eigengene E,它是模块第一主成分的值,本质为各个基因表达量的加权和,可以把它理解为这个模块的表达量。
图3-10-3 展示了各个模块基因根据TOM拓扑重叠矩阵聚类的结果。只有高度差(近似'1-拓扑重叠指数'得到的距离)在高度阈值(默认0.5,云流程可调整)以内的基因,才有可能被归为一个模块。grey是无法归类到任何模块的基因的集合
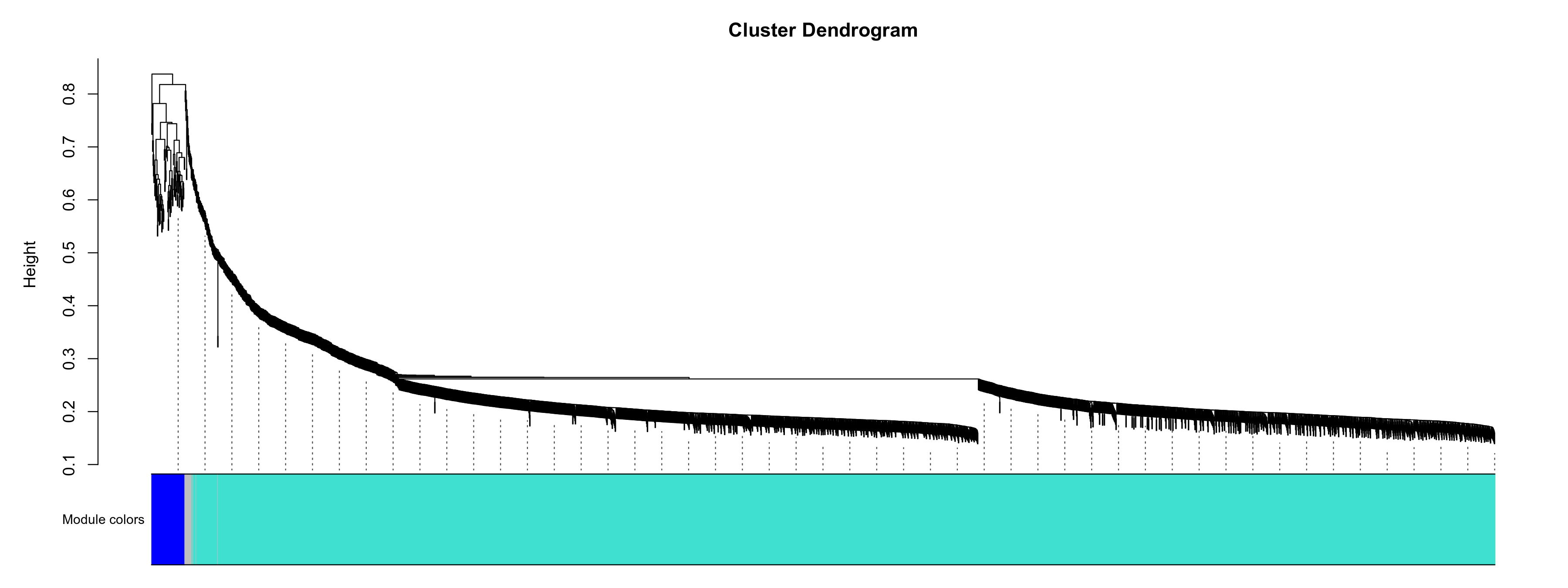
图3-10-3 模块基因聚类树
上方聚类树是所有基因根据TOM拓扑重叠矩阵聚类产生的树, 下方用不同颜色标注了不同模块。灰色基因是无法归类到任何模块的基因的集合
模块拓扑重叠网络
我们用网络图展示每个模块的基因的拓扑重叠指数,模块内相连的基因有较高的拓扑重叠指数
考虑到无标度网络的特征(连接度高的节点极少,连接度低的节点较多),同时也为了网络的可读性,对于每个模块,我们首先挑选拓扑重叠指数最高的1000个连接,计算每个节点的连接度(连线数量),最后挑选连接度最高的1个节点,以及与之相连的节点,作网络图(3-10-4)。这些挑选阈值可在云流程调整
图3-10-4 模块拓扑重叠网络
图片需要1~5分钟来加载,请耐心等候。为了提升交互体验,可打开一个新的网页操作网络
模块功能富集
为了研究每个模块主要参与哪些生物学过程,我们对每个模块进行了KEGG通路富集分析(ORA)以及GO条目富集分析。富集分析结果的解读请参照上文对富集分析结果的描述。模块富集到的功能,可以用来推断模块的功能。
模块关联表型
当老师提供表型数据(至少两个连续的数值型变量时),我们可以将模块的Module eigengene E(modules_ME.xls)与表型数据做相关分析,从而推断模块影响的表型

图3-10-5 模块与表型的相关性热图
格子的颜色对应相关系数(pearson)的大小,格子内上方标注了相关系数(pearson), 下方标注了相关系数的p值
3.11 参考基因组信息
11.ref_genome/ ├── genomic.fna [参考基因组序列信息] ├── genomic.gbk[参考基因组序列gbk文件] ├── genomic.gtf[参考基因组序列gtf文件] └── ref_genome_info.tsv[参考基因组信息]
参考基因组信息
以下是本次分析所用的参考物种信息:表3-11-1 参考基因组信息(ref_genome_info.tsv)
| Species_scientific_name | TaxID | kegg_species_code | Accession |
|---|---|---|---|
| Clostridioides difficile R20291 (Clostridium difficile R20291) (PCR-ribotype 027) | 645463 | cdl | GCA_000027105.1 |
- Species_scientific_name:参考基因组物种名,
- TaxID:物种ID,与kegg_species_code对应的物种缩写对应
- kegg_species_code:KEGG物种代码
- Accession:参考基因组在NCBI上的登录号
- 注:当使用kegg code的对应的基因组做参考基因组时,Species_scientific_name,Accession才会有值; 当kegg code为ko时,Species_scientific_name,TaxID,Accession都为空; 其他情况下,Species_scientific_name,Accession为空。
四 分析所用软件的版本
| 软件 | 版本 |
|---|---|
| fastp | 0.23.1 |
| RSeQC | 5.0.2 |
| bowtie2 | 2.5.3 |
| Rfam | 14.4 |
| Rockhopper | 2.03 |
| TransTermHP | v2.08 |
| diamond | v2.0.14 |
| RNAplex | 2.6.4 |
| ViennaRNA | 2.6.4 |
| RNAhybrid | 2.1.2 |
| sRNATarBase | 3.0 |
| BSRD | 2013 |
| Snippy | 4.2.1 |
| featureCounts | v2.0.1 |
| DESeq2 | 1.26.0 |
| edgeR | 3.28.1 |
| sva | 3.50.0 |
| pyComBat | 0.4.1 |
| clusterProfiler | 3.14.3 |
| WGCNA | 1.70.3 |